Regression
Regressionsmodelle sagen stetige, numerische Werte voraus Lineare und logistische Regression, Loss-Funktionen und Gradient Descent
Inhaltsverzeichnis
- Lineare Regression
- Prognosefehler und Loss
- Linearer Zusammenhang (Der schnelle Check)
- Ansätze zum Trainieren von Modellen
- Gradient Descent
- Logistische Regression
- Von der linearen zur logistischen Regression
- Zusammenfassung
- Abgrenzung zu verwandten Dokumenten
Lineare Regression
Die lineare Regression ist ein statistisches Verfahren, mit dem eine beobachtete abhängige Variable (y) durch eine oder mehrere unabhängige Variablen (x) erklärt wird. Dabei wird ein linearer Zusammenhang zwischen den Variablen angenommen.
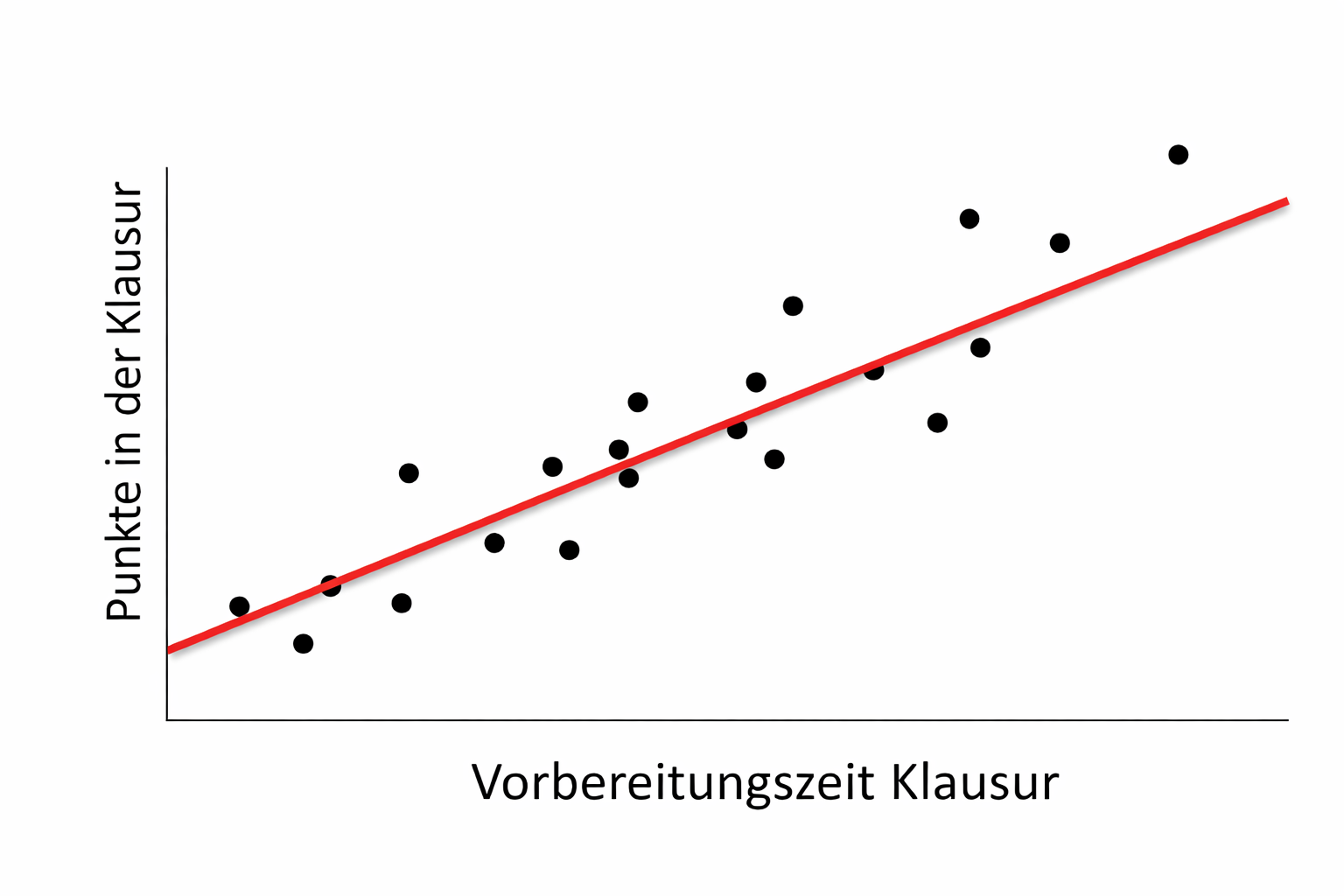
Die Regressionsgleichung
Der lineare Zusammenhang lässt sich als Gerade darstellen:
\[y = b + ax\]| Parameter | Bezeichnung | Bedeutung |
|---|---|---|
| b | Intercept (Y-Achsenabschnitt) | Wert von y, wenn x = 0 |
| a | Slope (Steigung) | Änderung von y pro Einheit x |
Prognosefehler und Loss
Was ist Loss?
Als Loss (Verlust) wird die Abweichung zwischen dem tatsächlichen Wert (y) und der Vorhersage (ŷ) bezeichnet. Der Loss quantifiziert, wie gut oder schlecht ein Modell vorhersagt.
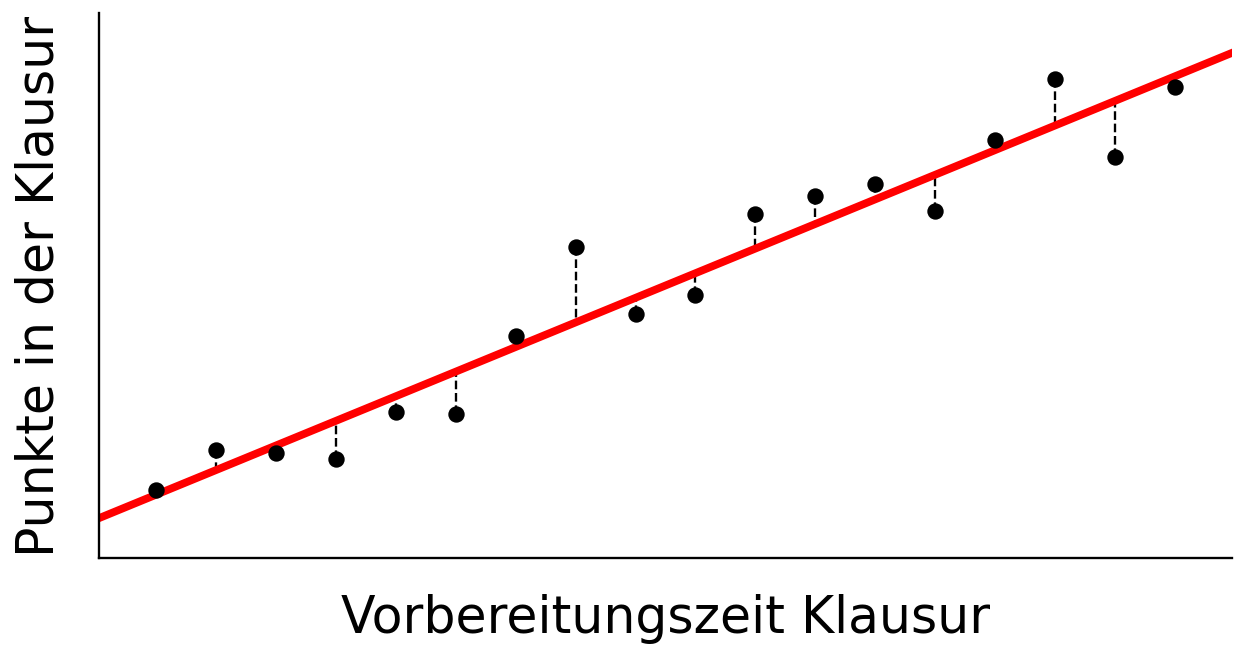
Wichtige Loss-Funktionen für Regression
| Loss-Funktion | Formel | Eigenschaften |
|---|---|---|
| MSE (Mean Squared Error) | $\frac{1}{n}\sum(y_i - \hat{y}_i)^2$ | Bestraft große Fehler stärker |
| MAE (Mean Absolute Error) | $\frac{1}{n}\sum|y_i - \hat{y}_i|$ | Robust gegenüber Ausreißern |
| RMSE (Root MSE) | $\sqrt{MSE}$ | Gleiche Einheit wie Zielvariable |
Linearer Zusammenhang (Der schnelle Check)
Vor der Modellbildung lässt sich prüfen, ob bzw. wie stark der lineare Zusammenhang zwischen den Merkmalen und der Zielvariable ist.
import pandas as pd
# Zeigt die Korrelation aller Spalten zur Zielvariable 'target'
correlations = df.corr()['target'].sort_values(ascending=False)
print(correlations)
- Werte nah bei 1 oder -1: Starker linearer Zusammenhang.
- Werte nah bei 0: Kein linearer Zusammenhang (die lineare Regression wird hier wahrscheinlich scheitern).
Ansätze zum Trainieren von Modellen
Das Training eines Modells bedeutet, die optimalen Parameter (Gewichte) zu finden, die den Loss minimieren. Dafür gibt es zwei grundlegende Ansätze:
flowchart TB
subgraph training["Trainingsansätze"]
direction LR
subgraph analytical["Analytische Optimierung"]
A1["Direkte Berechnung"]
A2["Methode der<br/>kleinsten Quadrate"]
A3["Geschlossene Lösung"]
end
subgraph iterative["Iterative Optimierung"]
I1["Schrittweise Anpassung"]
I2["Gradient Descent"]
I3["Konvergenz zum<br/>Optimum"]
end
end
style analytical fill:#e3f2fd
style iterative fill:#fff9c4
Vergleich der Ansätze
| Eigenschaft | Analytische Optimierung | Iterative Optimierung |
|---|---|---|
| Lösungsart | Direkte Ermittlung | Schrittweise Anpassung |
| Methode | Kleinste Quadrate | Gradient Descent |
| Algorithmus | Lineare Regression | Gradient Boosting, Neuronale Netze |
| Geschwindigkeit | Schnell bei einfachen Modellen | Schnell bei großen/komplexen Modellen |
| Nichtlineare Probleme | Ungeeignet | Geeignet |
| Abhängigkeit von Startwerten | Gering | Hoch |
| Konvergenz | Garantiert optimal | Lokale Minima möglich |
Wann welchen Ansatz verwenden?
flowchart TD
Q1{Lineares<br/>Problem?}
Q1 -->|Ja| Q2{Kleine<br/>Datenmenge?}
Q1 -->|Nein| I["Iterative<br/>Optimierung"]
Q2 -->|Ja| A["Analytische<br/>Optimierung"]
Q2 -->|Nein| Q3{Sehr große<br/>Datenmenge?}
Q3 -->|Ja| I
Q3 -->|Nein| A
style A fill:#e3f2fd
style I fill:#fff9c4
Gradient Descent
Intuition
Als Analogie dient ein Wanderer auf einem nebligen Berg, der den tiefsten Punkt (das Tal) sucht. Die Strategie: in die Richtung schreiten, in der es am steilsten bergab geht, Schritt für Schritt — bis das Tal erreicht ist.
flowchart TB
subgraph gd["Gradient Descent Prozess"]
direction TB
S["Start:<br/>Zufällige Gewichte"]
G["Gradient berechnen<br/>(Richtung des steilsten Anstiegs)"]
U["Gewichte updaten<br/>(in Gegenrichtung)"]
C{Konvergiert?}
E["Ende:<br/>Optimale Gewichte"]
S --> G
G --> U
U --> C
C -->|Nein| G
C -->|Ja| E
end
style S fill:#fff9c4
style G fill:#e3f2fd
style U fill:#e3f2fd
style E fill:#c8e6c9
Die Update-Regel
Die Gewichte werden nach folgender Regel angepasst:
\[w_{neu} = w_{alt} - \eta \cdot \nabla L\]| Symbol | Bedeutung |
|---|---|
| $w$ | Gewicht (Parameter) |
| $\eta$ | Lernrate (Schrittgröße) |
| $\nabla L$ | Gradient der Loss-Funktion |
Die Lernrate
Die Lernrate (Learning Rate) bestimmt die Schrittgröße bei der Optimierung:
flowchart LR
subgraph lr["Lernrate η"]
direction TB
subgraph small["η zu klein"]
S1["Langsame Konvergenz"]
S2["Viele Iterationen"]
end
subgraph optimal["η optimal"]
O1["Schnelle Konvergenz"]
O2["Stabiler Verlauf"]
end
subgraph large["η zu groß"]
L1["Oszillation"]
L2["Keine Konvergenz"]
end
end
style small fill:#fff9c4
style optimal fill:#c8e6c9
style large fill:#ffcdd2
Varianten von Gradient Descent
| Variante | Datenmenge pro Update | Eigenschaften |
|---|---|---|
| Batch GD | Alle Daten | Stabil, aber langsam |
| Stochastic GD | 1 Datenpunkt | Schnell, aber verrauscht |
| Mini-Batch GD | Kleine Teilmenge | Kompromiss aus beiden |
Logistische Regression
Von Regression zu Klassifikation
Trotz ihres Namens ist die logistische Regression ein Klassifikationsverfahren. Sie sagt Wahrscheinlichkeiten für kategoriale Ergebnisse voraus.
flowchart LR
subgraph comparison["Vergleich"]
direction TB
subgraph linear["Lineare Regression"]
L1["Ausgabe: Zahlenwert"]
L2["z.B. Preis: 250.000€"]
end
subgraph logistic["Logistische Regression"]
LO1["Ausgabe: Wahrscheinlichkeit"]
LO2["z.B. P(bestanden) = 0.85"]
end
end
style linear fill:#e3f2fd
style logistic fill:#c8e6c9
Das Problem der linearen Regression bei Klassifikation
Die lineare Regression kann Werte außerhalb von [0, 1] vorhersagen – das ergibt bei Wahrscheinlichkeiten keinen Sinn!
flowchart TB
subgraph problem["Problem"]
direction LR
P1["Lineare Vorhersage:<br/>y = -0.3"]
P2["Oder: y = 1.5"]
P3["❌ Ungültige<br/>Wahrscheinlichkeiten!"]
end
subgraph solution["Lösung"]
direction LR
S1["Sigmoid-Funktion"]
S2["Komprimiert auf [0, 1]"]
S3["✅ Gültige<br/>Wahrscheinlichkeiten"]
end
problem --> solution
style problem fill:#ffcdd2
style solution fill:#c8e6c9
Die Sigmoid-Funktion
Die Sigmoid-Funktion transformiert jeden Eingabewert in eine Wahrscheinlichkeit zwischen 0 und 1:
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]flowchart LR
subgraph sigmoid["Sigmoid-Transformation"]
direction TB
I["Lineare Kombination<br/>z = b + ax"]
S["Sigmoid-Funktion<br/>σ(z) = 1/(1+e⁻ᶻ)"]
O["Wahrscheinlichkeit<br/>P ∈ [0, 1]"]
I --> S --> O
end
style I fill:#fff9c4
style S fill:#e3f2fd
style O fill:#c8e6c9
Entscheidungsgrenze
Die logistische Regression teilt den Merkmalsraum durch eine lineare Entscheidungsgrenze:
flowchart TB
subgraph decision["<b>Entscheidungsgrenze"]
direction TB
subgraph threshold["<b>Schwellenwert (default:0.5)"]
T1["P(y=1) ≥ 0.5 → Klasse 1"]
T2["P(y=1) < 0.5 → Klasse 0"]
end
subgraph adjust["<b>Anpassbar je Use Case"]
A1["Höherer Schwellenwert:<br/>Weniger False Positives"]
A2["Niedrigerer Schwellenwert:<br/>Weniger False Negatives"]
end
end
style threshold fill:#e3f2fd
style adjust fill:#fff9c4
Von der linearen zur logistischen Regression
Die Transformation im Detail
flowchart TB
subgraph transformation["<b>Transformationsprozess"]
direction TB
subgraph step1["<b>1: Lineare Kombination"]
L["z = b + a₁x₁ + a₂x₂ + ..."]
L_note["Kann jeden Wert annehmen:<br/>z ∈ (-∞, +∞)"]
end
subgraph step2["<b>2: Sigmoid-Transformation"]
S["σ(z) = 1 / (1 + e⁻ᶻ)"]
S_note["Komprimiert auf:<br/>σ(z) ∈ (0, 1)"]
end
subgraph step3["<b>3: Klassifikation"]
C["Schwellenwert anwenden"]
C_note["σ(z) ≥ 0.5 → Klasse 1<br/>σ(z) < 0.5 → Klasse 0"]
end
step1 --> step2 --> step3
end
style step1 fill:#fff9c4
style step2 fill:#e3f2fd
style step3 fill:#c8e6c9
Vergleich: Lineare vs. Logistische Regression
| Aspekt | Lineare Regression | Logistische Regression |
|---|---|---|
| Aufgabe | Regression | Klassifikation |
| Ausgabe | Kontinuierlicher Wert | Wahrscheinlichkeit [0,1] |
| Aktivierung | Identität (keine) | Sigmoid |
| Loss-Funktion | MSE | Binary Cross-Entropy |
| Beispiel | Hauspreis vorhersagen | Spam erkennen |
Zusammenfassung
flowchart LR
subgraph summary["<b>Regression im Überblick"]
direction LR
subgraph linear["<b>Lineare Regression"]
direction TB
L1["Vorhersage numerischer Werte"] ~~~ L2["y = b + ax"] ~~~ L3["MSE als Loss"]
end
linear ~~~ logistic
subgraph logistic["<b>Logistische Regression"]
direction TB
LO1["Klassifikation"] ~~~ LO2["Sigmoid-Transformation"] ~~~ LO3["Wahrscheinlichkeiten [0,1]"]
end
logistic ~~~ training
subgraph training["<b>Training"]
direction TB
T1["Analytisch: Kleinste Quadrate"] ~~~ T2["Iterativ: Gradient Descent"] ~~~ T3["Ziel: Loss minimieren"]
end
end
style linear fill:#e3f2fd
style logistic fill:#c8e6c9
style training fill:#fff9c4
Abgrenzung zu verwandten Dokumenten
| Thema | Abgrenzung |
|---|---|
| Bewertung: Regression | Regressionsmodell macht Vorhersagen; Metriken (R2, MAE, RMSE) quantifizieren die Vorhersageguete |
| Bewertung: Klassifizierung | Lineare Regression vorhersagt kontinuierliche Werte; Logistische Regression gibt Klassenwahrscheinlichkeiten aus |
| Modellauswahl | Modellauswahl entscheidet, wann Regression angemessen ist; Regression ist die konkrete Implementierung |
Version: 1.0
Stand: Januar 2026
Kurs: Machine Learning. Verstehen. Anwenden. Gestalten.