Neuronale Netze
Künstliche neuronale Netze (KNN) sind dem biologischen Nervensystem nachempfundene Modelle, die komplexe nichtlineare Zusammenhänge zwischen Ein- und Ausgaben lernen können. Sie bilden das Fundament moderner Deep-Learning-Systeme.
Inhaltsverzeichnis
- Überblick
- Aufbau eines Neuronalen Netzes
- Aktivierungsfunktionen
- Training: Forward und Backward Pass
- Initialisierung der Gewichte
- Loss Functions
- Kombinationen für Unsupervised Learning
- Best Practices
- Abgrenzung zu verwandten Dokumenten
Überblick
Künstliche neuronale Netze (englisch: Artificial Neural Networks, ANN) sind Netze aus künstlichen Neuronen, die nach dem biologischen Vorbild des Nervensystems modelliert sind. Sie können sowohl für Klassifikation als auch für Regression eingesetzt werden.
flowchart LR
subgraph Input["Eingabeschicht"]
I1["Input 1"]
I2["Input 2"]
I3["Input n"]
end
subgraph Hidden["Verborgene Schicht(en)"]
H1((("N")))
H2((("N")))
H3((("N")))
H4((("N")))
end
subgraph Output["Ausgabeschicht"]
O1["Output"]
end
I1 --> H1 & H2
I2 --> H1 & H2 & H3 & H4
I3 --> H3 & H4
H1 --> O1
H2 --> O1
H3 --> O1
H4 --> O1
style I1 fill:#e3f2fd
style I2 fill:#e3f2fd
style I3 fill:#e3f2fd
style H1 fill:#fff9c4
style H2 fill:#fff9c4
style H3 fill:#fff9c4
style H4 fill:#fff9c4
style O1 fill:#c8e6c9
Grundlegende Bestandteile
Ein neuronales Netz besteht aus:
| Komponente | Beschreibung | Funktion |
|---|---|---|
| Neuronen/Knoten | Grundbausteine des Netzwerks | Verarbeiten Eingaben und erzeugen Ausgaben |
| Verbindungen | Gewichtete Kanten zwischen Neuronen | Übertragen Signale mit unterschiedlicher Stärke |
| Schichten (Layer) | Gruppierte Neuronen | Input → Hidden → Output |
Aufbau eines Neuronalen Netzes
Ein künstliches Neuron kann durch vier Basiselemente beschrieben werden:
flowchart LR
subgraph Eingaben["<b>Eingaben"]
X1["x₁"]
X2["x₂"]
X3["x₃"]
end
subgraph Gewichte["<b>Gewichte & Bias"]
W1["w₁"]
W2["w₂"]
W3["w₃"]
B["Bias b"]
end
subgraph Verarbeitung["<b>Neuron"]
SUM["Σ<br/>Übertragungsfunktion"]
ACT["f(x)<br/>Aktivierungsfunktion"]
end
Y["y<br/><b>Ausgabe"]
X1 --> W1 --> SUM
X2 --> W2 --> SUM
X3 --> W3 --> SUM
B --> SUM
SUM --> ACT --> Y
style SUM fill:#e3f2fd
style ACT fill:#fff9c4
style Y fill:#c8e6c9
Die vier Grundelemente
| Element | Beschreibung | Mathematisch |
|---|---|---|
| Gewichtung (Weights) | Jeder Eingang erhält ein Gewicht, das den Einfluss der Eingabe bestimmt | w₁, w₂, …, wₙ |
| Bias | Konstante additive Komponente, die den Schwellenwert verschiebt | b |
| Übertragungsfunktion | Berechnet die gewichtete Summe aller Eingaben | z = Σ(wᵢ · xᵢ) + b |
| Aktivierungsfunktion | Transformiert die Summe in die Ausgabe | y = f(z) |
Aktivierungsfunktionen
Die Aktivierungsfunktion bestimmt den möglichen Wertebereich der Ausgabe eines Neurons. Ohne Aktivierungsfunktionen wäre ein tiefes Netzwerk mathematisch äquivalent zu einem einfachen linearen Modell.
flowchart TD
subgraph Aktivierungsfunktionen["<b>Aktivierungsfunktionen"]
direction TB
subgraph Linear["Linear (Identity)"]
L["f(x) = x<br/>Wertebereich: (-∞, ∞)"]
end
subgraph Sigmoid["Sigmoid"]
S["f(x) = 1/(1+e⁻ˣ)<br/>Wertebereich: (0, 1)"]
end
subgraph Tanh["Tanh"]
T["f(x) = tanh(x)<br/>Wertebereich: (-1, 1)"]
end
subgraph ReLU["ReLU"]
R["f(x) = max(0, x)<br/>Wertebereich: (0, ∞)"]
end
end
style L fill:#e0e0e0
style S fill:#ffcdd2
style T fill:#c8e6c9
style R fill:#bbdefb
Übersicht der wichtigsten Aktivierungsfunktionen
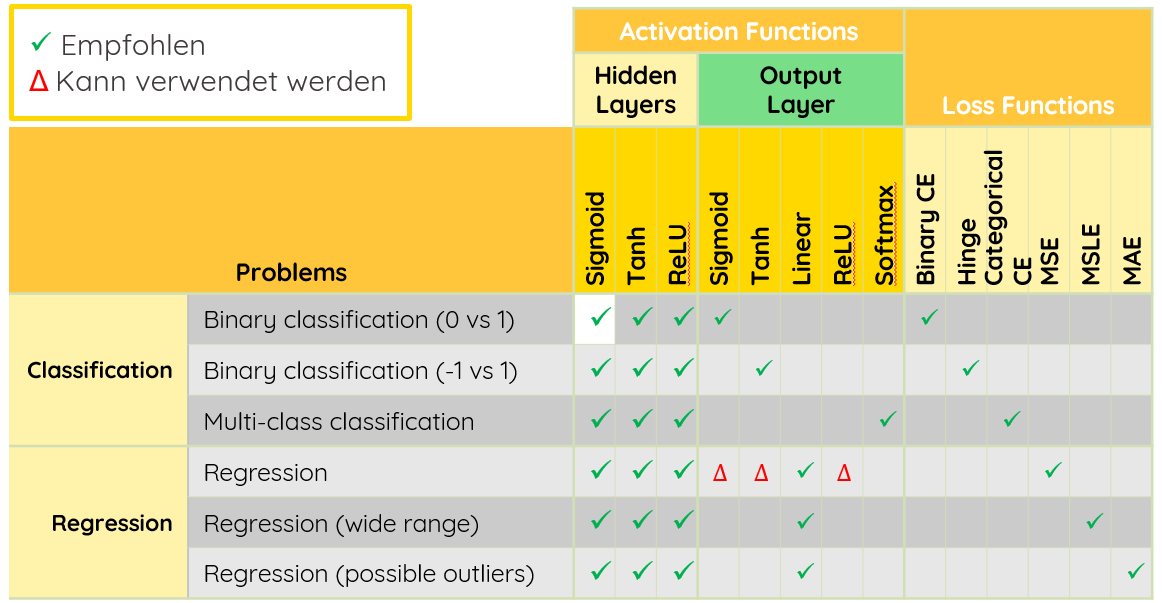
| Funktion | Formel | Wertebereich | Typischer Einsatz |
|---|---|---|---|
| Linear (Identity) | f(x) = x | (-∞, ∞) | Output-Layer bei Regression |
| Sigmoid | f(x) = 1/(1+e⁻ˣ) | (0, 1) | Binäre Klassifikation (Output) |
| Tanh | f(x) = tanh(x) | (-1, 1) | Hidden Layers, RNNs |
| ReLU | f(x) = max(0, x) | [0, ∞) | Hidden Layers (Standard) |
| Softmax | f(xᵢ) = eˣⁱ/Σeˣʲ | (0, 1), Summe = 1 | Multi-Class Klassifikation (Output) |
Wann welche Aktivierungsfunktion?
flowchart TD
START["Welche Aktivierungsfunktion?"]
LAYER{"Welche Schicht?"}
START --> LAYER
LAYER -->|Hidden Layer| HIDDEN["ReLU<br/>(oder Leaky ReLU, SELU)"]
LAYER -->|Output Layer| OUTPUT{"Aufgabe?"}
OUTPUT -->|Regression| REG["Linear"]
OUTPUT -->|Binäre Klassifikation| BIN["Sigmoid"]
OUTPUT -->|Multi-Class| MULTI["Softmax"]
style HIDDEN fill:#bbdefb
style REG fill:#e0e0e0
style BIN fill:#ffcdd2
style MULTI fill:#fff9c4
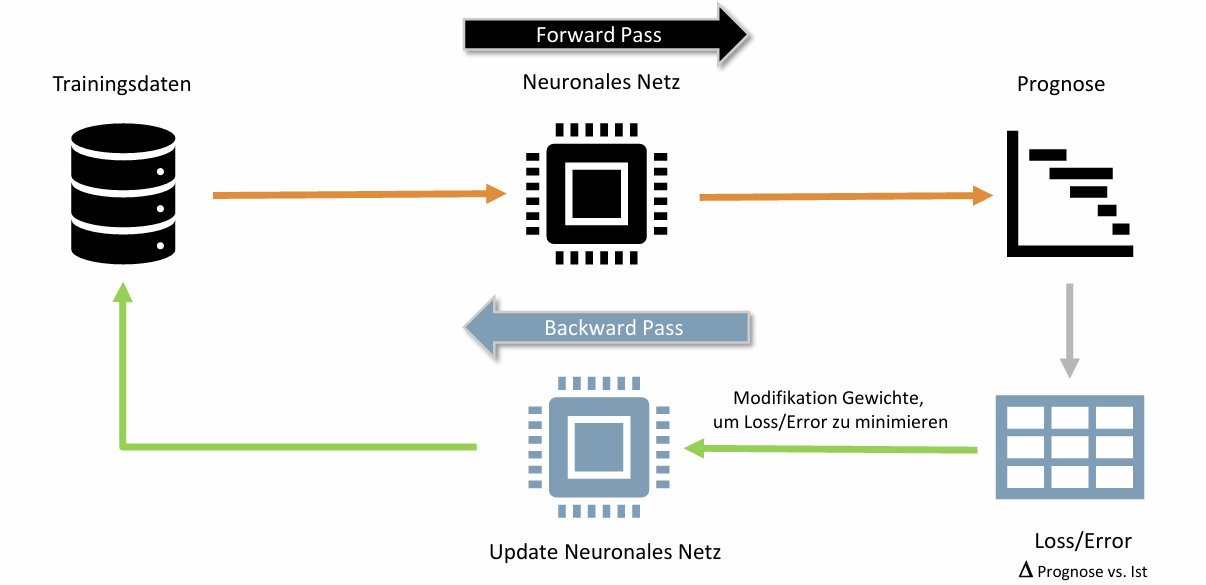
Training: Forward und Backward Pass
Das Training eines neuronalen Netzes erfolgt in zwei Phasen, die iterativ wiederholt werden:
flowchart LR
subgraph Forward["Forward Pass"]
direction TB
DATA["Trainingsdaten"] --> NN["Neuronales Netz"]
NN --> PRED["Vorhersage ŷ"]
end
subgraph Loss["Loss-Berechnung"]
PRED --> LOSS["Loss/Error<br/>L(y, ŷ)"]
ACTUAL["Tatsächlicher Wert y"] --> LOSS
end
subgraph Backward["Backward Pass"]
LOSS --> GRAD["Gradienten<br/>berechnen"]
GRAD --> UPDATE["Gewichte<br/>aktualisieren"]
UPDATE --> NN
end
style DATA fill:#e3f2fd
style PRED fill:#fff9c4
style LOSS fill:#ffcdd2
style UPDATE fill:#c8e6c9
Der Trainingszyklus
- Forward Pass: Eingabedaten werden durch das Netz propagiert → Vorhersage
- Loss-Berechnung: Abweichung zwischen Vorhersage und tatsächlichem Wert
- Backward Pass: Gradienten werden rückwärts durch das Netz berechnet
- Update: Gewichte werden angepasst, um den Loss zu minimieren
Initialisierung der Gewichte
Die Wahl der initialen Gewichte hat großen Einfluss auf das Training. Schlechte Initialisierung kann zu langsamer Konvergenz oder gar keinem Lernen führen.
Probleme bei falscher Initialisierung
| Problem | Ursache | Konsequenz |
|---|---|---|
| Nullgewichte | Alle Gewichte = 0 | Neuronen bleiben inaktiv |
| Zu große Werte | Gewichte » 1 | Sättigung der Aktivierungsfunktion |
| Symmetrische Gewichte | Alle Gewichte identisch | Neuronen lernen dasselbe |
Moderne Initialisierungsmethoden
flowchart TD
INIT["Gewichts-Initialisierung"]
INIT --> XAVIER["Xavier/Glorot<br/>Varianz = 2/(n_in + n_out)"]
INIT --> HE["He-Initialisierung<br/>Varianz = 2/n_in"]
XAVIER --> |"Sigmoid, Tanh"| SIGMOID_NET["Für Sigmoid/Tanh-Netze"]
HE --> |"ReLU"| RELU_NET["Für ReLU-Netze"]
style XAVIER fill:#c8e6c9
style HE fill:#bbdefb
Loss Functions
Die Loss-Funktion (Verlustfunktion) quantifiziert, wie weit die Vorhersagen des Modells von den tatsächlichen Werten abweichen. Sie ist das Optimierungsziel beim Training.
Übersicht: Aufgabe → Loss Function
| Aufgabe | Loss Function | Beschreibung |
|---|---|---|
| Regression | MSE (Mean Squared Error) | Mittlerer quadratischer Fehler |
| Regression | MAE (Mean Absolute Error) | Mittlerer absoluter Fehler |
| Binäre Klassifikation | Binary Cross-Entropy | Logarithmischer Verlust für 2 Klassen |
| Multi-Class Klassifikation | Categorical Cross-Entropy | Logarithmischer Verlust für n Klassen |
Kombinationen: Aktivierung + Loss
flowchart TD
TASK{"Aufgabe?"}
TASK -->|Regression| REG["Output: Linear<br/>Loss: MSE oder MAE"]
TASK -->|Binäre Klassifikation| BIN["Output: Sigmoid<br/>Loss: Binary Cross-Entropy"]
TASK -->|Multi-Class| MULTI["Output: Softmax<br/>Loss: Categorical Cross-Entropy"]
style REG fill:#e3f2fd
style BIN fill:#ffcdd2
style MULTI fill:#fff9c4
Empfohlene Kombinationen für Supervised Learning
Kombinationen für Unsupervised Learning
Neuronale Netze werden auch im unüberwachten Lernen eingesetzt:
| Use Case | Hidden Aktivierung | Output Aktivierung | Loss Function |
|---|---|---|---|
| Clustering | ReLU, Leaky ReLU | Softmax | KL-Divergenz, Cosine Similarity |
| Anomalieerkennung | ReLU, Tanh, Sigmoid | Sigmoid | MSE, Binary Cross-Entropy |
| Dimensionsreduktion | ReLU, Leaky ReLU, Tanh | Linear, Sigmoid | MSE |
| Generative Modelle (GAN) | Leaky ReLU, SELU | Tanh (Generator), Sigmoid (Discriminator) | Binary Cross-Entropy |
Best Practices
Checkliste für neuronale Netze
- Daten normalisieren: StandardScaler oder MinMaxScaler verwenden
- Passende Architektur: Starte klein, erweitere bei Bedarf
- ReLU in Hidden Layers: Standard-Wahl für die meisten Aufgaben
- Passende Output-Aktivierung: Sigmoid (binär), Softmax (multi-class), Linear (Regression)
- Passende Loss-Funktion: Muss zur Aufgabe passen
- Gewichtsinitialisierung: He für ReLU, Xavier für Sigmoid/Tanh
Häufige Fehler vermeiden
| Fehler | Problem | Lösung | |——–|———|——–| | Sigmoid in allen Hidden Layers | Vanishing Gradients | ReLU verwenden | | Softmax für binäre Klassifikation | Unnötige Komplexität | Sigmoid verwenden | | Linear-Aktivierung in Hidden Layers | Keine Nichtlinearität | ReLU, Tanh verwenden | | Falsche Loss-Funktion | Training konvergiert nicht | Loss an Aufgabe anpassen | | Zu große Lernrate | Training instabil | Lernrate reduzieren |
Abgrenzung zu verwandten Dokumenten
| Thema | Abgrenzung |
|---|---|
| Lineare Regression | Neuronale Netze lernen nichtlineare Funktionen durch mehrere Schichten; Regression modelliert nur lineare Beziehungen |
| Modellauswahl | Neuronale Netze sind eine Modellklasse; Modellauswahl entscheidet, wann NN sinnvoll ist — z.B. bei grossen Datenmgen |
| Spezielle Neuronale Netze | Dieses Dokument behandelt Grundlagen (MLP, Aktivierung, Training); spezialisierte Architekturen (CNN, RNN) folgen dort |
Version: 1.0
Stand: Januar 2026
Kurs: Machine Learning. Verstehen. Anwenden. Gestalten.