Silhouette-Koeffizient
Der Silhouette-Koeffizient bewertet die Qualität von Clustering-Ergebnissen, indem er misst, wie gut Datenpunkte zu ihrem eigenen Cluster passen im Vergleich zu benachbarten Clustern.
Inhaltsverzeichnis
- Grundkonzept
- Mathematische Berechnung
- Wertebereich und Interpretation
- Silhouette-Plot
- Best Practices
- Abgrenzung zu verwandten Dokumenten
Grundkonzept
Der Silhouette-Koeffizient ist ein weit verbreitetes Maß zur Bewertung der Qualität einer Clusterbildung. Er beantwortet die zentrale Frage: Wie gut passt jeder Datenpunkt zu seinem zugewiesenen Cluster?
flowchart LR
subgraph Bewertung["Silhouette-Bewertung"]
A[Datenpunkt] --> B{Vergleich}
B --> C[Nähe zum<br/>eigenen Cluster]
B --> D[Abstand zum<br/>nächsten Cluster]
C --> E[Silhouette-Wert]
D --> E
end
style A fill:#e1f5fe
style E fill:#c8e6c9
Kernidee
Der Koeffizient kombiniert zwei Perspektiven:
| Aspekt | Beschreibung | Wünschenswert |
|---|---|---|
| Kompaktheit | Wie nah ist der Punkt an den anderen Punkten seines Clusters? | Möglichst nah |
| Separation | Wie weit ist der Punkt von Punkten anderer Cluster entfernt? | Möglichst weit |
Ein gutes Clustering zeichnet sich durch hohe Kompaktheit innerhalb der Cluster und große Separation zwischen den Clustern aus.
Mathematische Berechnung
Formel
Für jeden Datenpunkt x wird der Silhouette-Wert s(x) berechnet:
\[s(x) = \frac{b(x) - a(x)}{\max\{a(x), b(x)\}}\]Dabei gilt:
| Symbol | Bedeutung |
|---|---|
| a(x) | Durchschnittlicher Abstand von x zu allen anderen Punkten im eigenen Cluster (Intra-Cluster-Distanz) |
| b(x) | Durchschnittlicher Abstand von x zu allen Punkten im nächstgelegenen fremden Cluster (Inter-Cluster-Distanz) |
Berechnungsschritte
flowchart TD
subgraph Schritt1["<b>#1 Intra-Cluster-Distanz a(x)"]
A1[Wähle Datenpunkt x] --> A2[Berechne Abstände zu allen<br/>anderen Punkten im eigenen Cluster]
A2 --> A3[Bilde Durchschnitt → a#40;x#41;]
end
subgraph Schritt2["<b>#2 Inter-Cluster-Distanz b(x)"]
B1[Für jeden fremden Cluster] --> B2[Berechne durchschnittlichen<br/>Abstand von x zu allen Punkten]
B2 --> B3[Wähle Minimum → b#40;x#41;]
end
subgraph Schritt3["<b>#3 Silhouette-Wert"]
C1["s(x) = (b(x) - a(x)) / max{a(x), b(x)}"]
end
A3 --> C1
B3 --> C1
style A3 fill:#fff3e0
style B3 fill:#e3f2fd
style C1 fill:#c8e6c9
Wertebereich und Interpretation
Der Silhouette-Koeffizient liegt immer im Bereich [-1, +1]:
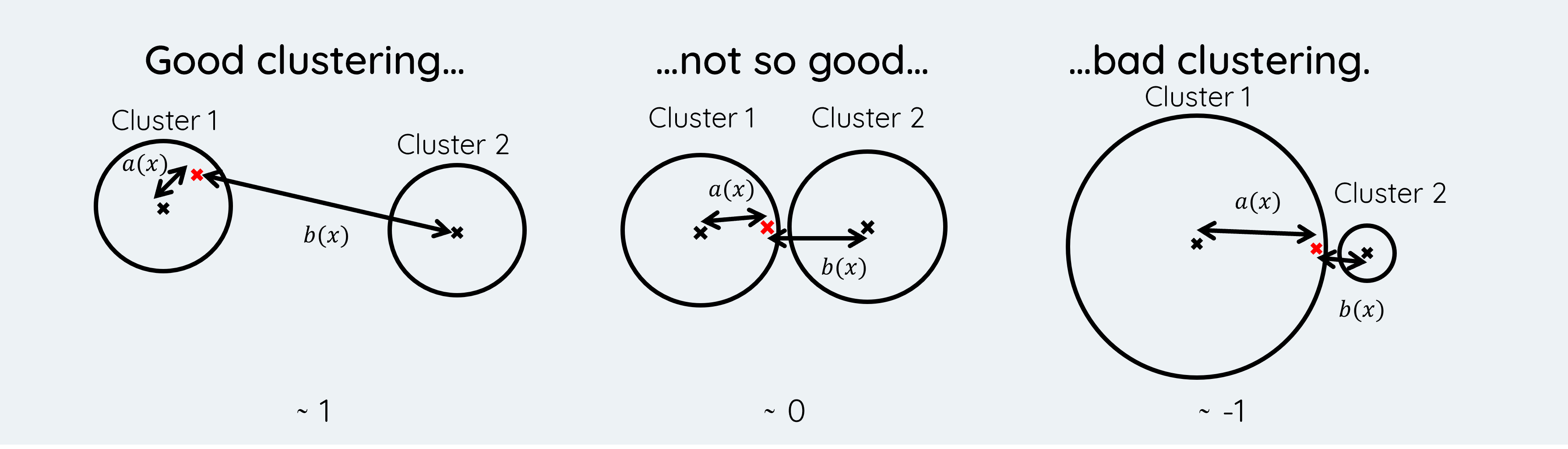
Detaillierte Interpretation
| Wertebereich | Bedeutung | Handlungsempfehlung |
|---|---|---|
| 0.71 – 1.00 | Starke Clusterstruktur | Clustering ist sehr gut |
| 0.51 – 0.70 | Vernünftige Struktur | Clustering ist akzeptabel |
| 0.26 – 0.50 | Schwache Struktur | Clustering überprüfen |
| ≤ 0.25 | Keine substanzielle Struktur | Clustering fragwürdig |
| < 0 | Falsche Zuordnung | Punkt gehört wahrscheinlich in anderes Cluster |
Interpretation der Szenarien
| Szenario | Charakteristik | Silhouette-Wert |
|---|---|---|
| Gutes Clustering | Punkt liegt zentral im eigenen Cluster, weit entfernt von anderen | ≈ +1 |
| Grenzfall | Punkt liegt zwischen zwei Clustern, könnte zu beiden gehören | ≈ 0 |
| Schlechtes Clustering | Punkt ist näher an fremdem Cluster als am eigenen | ≈ -1 |
Silhouette-Plot
Der Silhouette-Plot ist eine Visualisierung, die die Qualität aller Datenpunkte auf einen Blick zeigt.
Aufbau des Plots
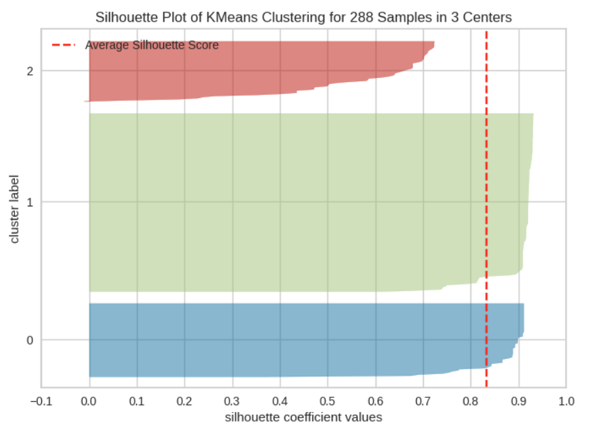
Interpretation des Silhouette-Plots
| Merkmal | Gute Qualität | Schlechte Qualität |
|---|---|---|
| Balkenbreite | Breite, gleichmäßige Balken | Schmale, unregelmäßige Balken |
| Negative Werte | Keine oder wenige | Viele Balken links der 0-Linie |
| Clustergröße | Ähnlich große Cluster | Stark unterschiedliche Größen |
| Durchschnittslinie | Weit rechts (> 0.5) | Nahe bei 0 oder links |
Anwendungen des Silhouette-Plots
Der Silhouette-Plot hilft bei wichtigen Entscheidungen:
flowchart TD
SP[Silhouette-Plot] --> A[Optimale Cluster-Anzahl<br/>finden]
SP --> B[Problematische<br/>Datenpunkte identifizieren]
SP --> C[Cluster-Qualität<br/>vergleichen]
SP --> D[Algorithmus-Wahl<br/>validieren]
A --> A1[Plot für k=2,3,4,...<br/>erstellen und vergleichen]
B --> B1[Punkte mit s < 0<br/>untersuchen]
C --> C1[Durchschnittlichen<br/>Silhouette-Wert berechnen]
style SP fill:#e1f5fe
style A fill:#c8e6c9
style B fill:#fff3e0
style C fill:#f3e5f5
style D fill:#e8f5e9
Best Practices
Empfehlungen für die Praxis
flowchart TD
subgraph Vorbereitung["+1 Vorbereitung"]
V1[Daten skalieren<br/>vor dem Clustering]
V2[Ausreißer<br/>behandeln]
end
subgraph Analyse["#2 Analyse"]
A1[Mehrere k-Werte<br/>testen]
A2[Silhouette-Plot<br/>visuell prüfen]
A3[Einzelne Cluster<br/>untersuchen]
end
subgraph Validierung["#3 Validierung"]
VAL1[Mit anderen Metriken<br/>kombinieren]
VAL2[Fachliche<br/>Interpretation]
end
Vorbereitung --> Analyse --> Validierung
style V1 fill:#e3f2fd
style V2 fill:#e3f2fd
style A1 fill:#c8e6c9
style A2 fill:#c8e6c9
style A3 fill:#c8e6c9
style VAL1 fill:#fff3e0
style VAL2 fill:#fff3e0
Wichtige Hinweise
| Aspekt | Empfehlung |
|---|---|
| Skalierung | Immer Daten vor dem Clustering skalieren (StandardScaler oder MinMaxScaler) |
| Stichprobengröße | Bei sehr großen Datensätzen ggf. Stichprobe verwenden |
| Distanzmetrik | Silhouette nutzt standardmäßig euklidische Distanz – bei anderen Distanzen anpassen |
| Interpretation | Silhouette allein reicht nicht – immer auch fachlich interpretieren |
| Grenzwert | Silhouette > 0.5 ist ein guter Richtwert, aber kontextabhängig |
Häufige Fehler vermeiden
| Fehler | Problem | Lösung |
|---|---|---|
| Unskalierte Daten | Features mit größerem Wertebereich dominieren | StandardScaler verwenden |
| Nur Durchschnitt betrachten | Versteckt problematische Cluster | Silhouette-Plot analysieren |
| k=1 testen | Silhouette für einzelnes Cluster undefiniert | Minimum k=2 verwenden |
| Negative Werte ignorieren | Falsch zugeordnete Punkte übersehen | Punkte mit s < 0 untersuchen |
Abgrenzung zu verwandten Dokumenten
| Dokument | Frage |
|---|---|
| K-Means und DBSCAN | Wie funktionieren die wichtigsten Clustering-Verfahren selbst? |
| Bewertung allgemein | Welche Bewertungslogik gilt über einzelne Verfahren hinaus? |
| Bewertung Anomalie | Wie verändert sich die Bewertung, wenn nicht Cluster, sondern Ausreißer im Fokus stehen? |
| Skalierung | Warum ist Vorverarbeitung für Distanzverfahren besonders wichtig? |
Version: 1.0
Stand: Januar 2026
Kurs: Machine Learning. Verstehen. Anwenden. Gestalten.