Bewertung Klassifizierung
Klassifikationsmodelle erfordern spezifische Metriken zur Leistungsbewertung.
Dieses Kapitel behandelt die wichtigsten Werkzeuge: Confusion Matrix, Precision, Recall, F1-Score, Cohen’s Kappa, ROC-Kurve und AUC. Besondere Aufmerksamkeit gilt dem Umgang mit unausgewogenen Datensätzen.
Inhaltsverzeichnis
- Confusion Matrix
- Metriken aus der Confusion Matrix
- Multi-Class Confusion Matrix
- Cohen’s Kappa
- ROC-Kurve (Receiver Operating Characteristic)
- Area Under the Curve (AUC)
- Umgang mit unausgewogenen Klassen
- Zusammenfassung: Metrik-Übersicht
- Weiterführende Themen
- Abgrenzung zu verwandten Dokumenten
Confusion Matrix
Die Konfusionsmatrix (Confusion Matrix) ist das fundamentale Werkzeug zur Bewertung von Klassifikationsmodellen. Sie zeigt, wie die Vorhersagen des Modells mit den tatsächlichen Werten übereinstimmen.
[!NOTE] Ausgangspunkt
Viele Klassifikationsmetriken sind direkte Ableitungen aus TP, FP, TN und FN der Confusion Matrix.
Aufbau der binären Confusion Matrix
flowchart TB
subgraph matrix["<b>Confusion Matrix"]
subgraph row2["Predicted: <b>Negative"]
FN["✗ False Negative<br/>(FN)<br/>Fälschlich als negativ erkannt<br/><i>Typ-II-Fehler</i>"]
TN["✓ True Negative<br/>(TN)<br/>Richtig als negativ erkannt"]
end
subgraph row1["Predicted: <b>Positive"]
TP["✓ True Positive<br/>(TP)<br/>Richtig als positiv erkannt"]
FP["✗ False Positive<br/>(FP)<br/>Fälschlich als positiv erkannt<br/><i>Typ-I-Fehler</i>"]
end
end
style TP fill:#c8e6c9,stroke:#2e7d32
style TN fill:#c8e6c9,stroke:#2e7d32
style FP fill:#ffcdd2,stroke:#c62828
style FN fill:#ffcdd2,stroke:#c62828
Die vier Kategorien
| Kategorie | Beschreibung | Beispiel (Spam-Erkennung) |
|---|---|---|
| True Positive (TP) | Positives Ergebnis vorhergesagt, tatsächlich positiv | Spam korrekt als Spam erkannt |
| False Positive (FP) | Positives Ergebnis vorhergesagt, tatsächlich negativ | Normale E-Mail fälschlich als Spam markiert |
| True Negative (TN) | Negatives Ergebnis vorhergesagt, tatsächlich negativ | Normale E-Mail korrekt durchgelassen |
| False Negative (FN) | Negatives Ergebnis vorhergesagt, tatsächlich positiv | Spam fälschlich als normale E-Mail durchgelassen |
Implementierung mit scikit-learn
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Confusion Matrix berechnen
cm = confusion_matrix(target_test, target_pred)
print("Confusion Matrix:")
print(cm)
# Visualisierung
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=['Negativ', 'Positiv'])
disp.plot(cmap='Blues')
plt.title('Confusion Matrix')
plt.show()
Metriken aus der Confusion Matrix
Aus den vier Grundwerten der Confusion Matrix lassen sich verschiedene Leistungsmetriken ableiten, die unterschiedliche Aspekte der Modellqualität bewerten.
flowchart LR
subgraph cm["Confusion Matrix"]
TP["TP"]
FP["FP"]
FN["FN"]
TN["TN"]
end
subgraph metrics["Abgeleitete Metriken"]
ACC["Accuracy<br/>(TP+TN) / Alle"]
PRE["Precision<br/>TP / (TP+FP)"]
REC["Recall<br/>TP / (TP+FN)"]
F1["F1-Score<br/>2×(P×R)/(P+R)"]
end
cm --> metrics
style ACC fill:#e3f2fd
style PRE fill:#e8f5e9
style REC fill:#fff3e0
style F1 fill:#f3e5f5
Accuracy (Genauigkeit)
Die Accuracy misst den Anteil aller korrekten Vorhersagen an der Gesamtzahl der Fälle.
\[\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}\]from sklearn.metrics import accuracy_score
accuracy = accuracy_score(target_test, target_pred)
print(f"Accuracy: {accuracy:.4f}")
[!WARNING] Accuracy-Falle bei Imbalance
Ein Modell kann hohe Accuracy erreichen und trotzdem die relevante Minderheitsklasse kaum erkennen.
Precision (Relevanz/Präzision)
Die Precision gibt an, wie viele der als positiv vorhergesagten Fälle tatsächlich positiv sind.
\[\text{Precision} = \frac{TP}{TP + FP}\]from sklearn.metrics import precision_score
precision = precision_score(target_test, target_pred)
print(f"Precision: {precision:.4f}")
Wann ist Precision wichtig?
- Wenn False Positives teuer oder problematisch sind
- Beispiel: Spam-Filter (normale E-Mails sollen nicht blockiert werden)
- Beispiel: Qualitätskontrolle (gute Produkte sollen nicht aussortiert werden)
Recall (Sensitivität/Trefferquote)
Der Recall gibt an, wie viele der tatsächlich positiven Fälle korrekt erkannt wurden.
\[\text{Recall} = \frac{TP}{TP + FN}\]from sklearn.metrics import recall_score
recall = recall_score(target_test, target_pred)
print(f"Recall: {recall:.4f}")
Wann ist Recall wichtig?
- Wenn False Negatives teuer oder gefährlich sind
- Beispiel: Krankheitsdiagnose (Kranke sollen nicht übersehen werden)
- Beispiel: Betrugserkennung (Betrug soll nicht unentdeckt bleiben)
F1-Score
Der F1-Score ist das harmonische Mittel aus Precision und Recall und bietet eine ausgewogene Bewertung.
\[\text{F1-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\]from sklearn.metrics import f1_score
f1 = f1_score(target_test, target_pred)
print(f"F1-Score: {f1:.4f}")
Interpretation: Der F1-Score ist besonders nützlich, wenn ein Gleichgewicht zwischen Precision und Recall gewünscht ist und die Klassen unausgewogen sind.
Beispielrechnung
Gegeben sei folgende Confusion Matrix:
| Predicted: Positiv | Predicted: Negativ | |
|---|---|---|
| Actual: Positiv | TP = 20 | FN = 3 |
| Actual: Negativ | FP = 5 | TN = 15 |
Berechnungen:
- Accuracy: (20 + 15) / (20 + 15 + 5 + 3) = 35 / 43 ≈ 0.81
- Precision: 20 / (20 + 5) = 20 / 25 = 0.80
- Recall: 20 / (20 + 3) = 20 / 23 ≈ 0.87
- F1-Score: 2 × (0.80 × 0.87) / (0.80 + 0.87) ≈ 0.83
Kompletter Classification Report
from sklearn.metrics import classification_report
print(classification_report(target_test, target_pred, target_names=['Negativ', 'Positiv']))
Beispielausgabe:
precision recall f1-score support
Negativ 0.83 0.75 0.79 20
Positiv 0.80 0.87 0.83 23
accuracy 0.81 43
macro avg 0.82 0.81 0.81 43
weighted avg 0.82 0.81 0.81 43
Multi-Class Confusion Matrix
Bei Klassifikationsproblemen mit mehr als zwei Klassen wird die Confusion Matrix entsprechend erweitert. Die Berechnung der Metriken erfolgt dann klassenweise.
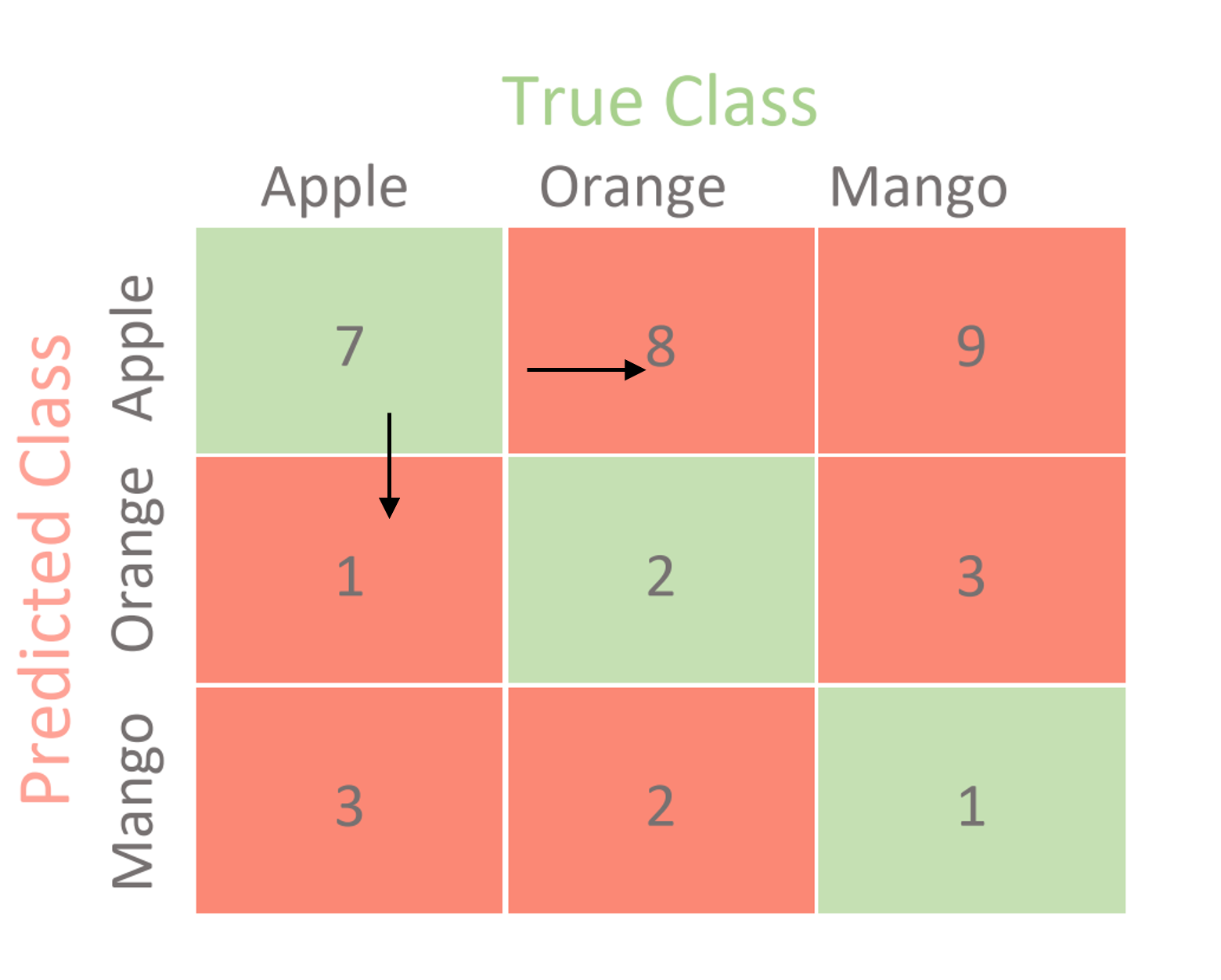
Berechnung für einzelne Klassen
Bei Multi-Class-Problemen werden TP, TN, FP und FN für jede Klasse einzeln berechnet:
Beispiel für Klasse “Apple” aus der obigen Matrix:
| Metrik | Berechnung | Ergebnis |
|---|---|---|
| TP | Korrekt als Apple klassifiziert | 7 |
| FN | Apple, aber als andere Klasse klassifiziert | 1 + 3 = 4 |
| FP | Andere Klasse, aber als Apple klassifiziert | 8 + 9 = 17 |
| TN | Andere Klasse, korrekt nicht als Apple | 2 + 3 + 2 + 1 = 8 |
Implementierung
from sklearn.metrics import confusion_matrix, classification_report
# Multi-Class Confusion Matrix
cm = confusion_matrix(target_test, target_pred)
print("Confusion Matrix:")
print(cm)
# Classification Report für alle Klassen
print("\nClassification Report:")
print(classification_report(target_test, target_pred, target_names=['Apple', 'Orange', 'Banana']))
Aggregationsstrategien
Bei Multi-Class-Problemen gibt es verschiedene Möglichkeiten, die Metriken zu aggregieren:
| Strategie | Beschreibung | Verwendung |
|---|---|---|
| Macro Average | Ungewichteter Durchschnitt aller Klassen | Wenn alle Klassen gleich wichtig sind |
| Weighted Average | Gewichtet nach Klassenhäufigkeit | Bei unausgewogenen Klassen |
| Micro Average | Gesamtsumme aller TP, FP, FN | Für Gesamtleistung |
from sklearn.metrics import precision_score, recall_score, f1_score
# Verschiedene Averaging-Strategien
print(f"Macro F1: {f1_score(target_test, target_pred, average='macro'):.4f}")
print(f"Weighted F1: {f1_score(target_test, target_pred, average='weighted'):.4f}")
print(f"Micro F1: {f1_score(target_test, target_pred, average='micro'):.4f}")
Cohen’s Kappa
Cohen’s Kappa ist eine robustere Metrik als die Accuracy, da sie die zufällige Übereinstimmung berücksichtigt. Sie ist besonders wertvoll bei unausgewogenen Klassen.
Interpretation
flowchart LR
subgraph scale["<b>Cohen's Kappa Skala"]
direction LR
S1["-1<br/>Schlechte<br/>Übereinstimmung"]
S2["0<br/>Zufällige<br/>Übereinstimmung"]
S3["0.2<br/>Leichte"]
S4["0.4<br/>Ausreichende"]
S5["0.6<br/>Moderate"]
S6["0.8<br/>Beachtliche"]
S7["1<br/>Perfekte<br/>Übereinstimmung"]
end
S1 --> S2 --> S3 --> S4 --> S5 --> S6 --> S7
style S1 fill:#ffcdd2
style S2 fill:#fff9c4
style S3 fill:#fff9c4
style S4 fill:#e8f5e9
style S5 fill:#c8e6c9
style S6 fill:#a5d6a7
style S7 fill:#81c784
| Kappa-Wert | Interpretation |
|---|---|
| κ < 0.0 | Schlechte Übereinstimmung (schlechter als Zufall) |
| κ ≤ 0.2 | Leichte Übereinstimmung |
| κ ≤ 0.4 | Ausreichende Übereinstimmung |
| κ ≤ 0.6 | Moderate Übereinstimmung |
| κ ≤ 0.8 | Beachtliche Übereinstimmung |
| κ > 0.8 | (Fast) vollständige Übereinstimmung |
Berechnung
\[\kappa = \frac{p_o - p_e}{1 - p_e}\]Wobei:
- $p_o$ = beobachtete Übereinstimmung (Accuracy)
- $p_e$ = erwartete zufällige Übereinstimmung
Implementierung
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(target_test, target_pred)
print(f"Cohen's Kappa: {kappa:.4f}")
Vorteile gegenüber Accuracy
import numpy as np
from sklearn.metrics import accuracy_score, cohen_kappa_score
# Beispiel: Unausgewogener Datensatz (90% Klasse 0)
target_true = np.array([0]*90 + [1]*10)
target_pred_naive = np.array([0]*100) # Sagt immer 0 voraus
print(f"Accuracy: {accuracy_score(target_true, target_pred_naive):.2f}") # 0.90
print(f"Cohen's Kappa: {cohen_kappa_score(target_true, target_pred_naive):.2f}") # 0.00
# Kappa zeigt, dass das Modell nicht besser als Zufall ist!
ROC-Kurve (Receiver Operating Characteristic)
Die ROC-Kurve ist ein leistungsstarkes Werkzeug zur Visualisierung der Klassifikationsleistung über verschiedene Schwellenwerte hinweg.
Grundkonzept
flowchart TB
subgraph roc["<b>ROC-Kurve Interpretation"]
subgraph axes["<b>Achsen"]
X["X-Achse: False Positive Rate (FPR)<br/>= FP / (FP + TN)<br/>= 1 - Specificity"]
Y["Y-Achse: True Positive Rate (TPR)<br/>= TP / (TP + FN)<br/>= Sensitivity/Recall"]
end
subgraph interpretation["<b>Interpretation"]
I1["Kurve oben links → Gutes Modell"]
I2["Diagonale → Zufälliges Raten"]
I3["Kurve unter Diagonale → Schlechter als Zufall"]
end
end
Sensitivität und Spezifität
| Metrik | Formel | Beschreibung |
|---|---|---|
| Sensitivität (TPR) | TP / (TP + FN) | Anteil der korrekt erkannten positiven Fälle |
| Spezifität (TNR) | TN / (TN + FP) | Anteil der korrekt erkannten negativen Fälle |
| False Positive Rate | FP / (FP + TN) = 1 - Spezifität | Anteil der fälschlich als positiv erkannten negativen Fälle |
Implementierung
from sklearn.metrics import roc_curve, RocCurveDisplay
import matplotlib.pyplot as plt
# Wahrscheinlichkeiten berechnen (nicht Labels!)
target_proba = model.predict_proba(data_test)[:, 1]
# ROC-Kurve
fpr, tpr, thresholds = roc_curve(target_test, target_proba)
# Visualisierung
RocCurveDisplay.from_predictions(target_test, target_proba)
plt.plot([0, 1], [0, 1], 'k--', label='Zufall')
plt.title('ROC-Kurve')
plt.legend()
plt.show()
Schwellenwert-Optimierung
Der Standard-Schwellenwert von 0.5 ist nicht immer optimal. Je nach Anwendungsfall kann ein anderer Schwellenwert sinnvoller sein.
flowchart TD
subgraph decision["Schwellenwert-Entscheidung"]
Q1{Welche Fehler<br/>sind kritischer?}
Q1 -->|"FN kritisch<br/>(Krankheit übersehen)"| A1["Niedrigerer Schwellenwert<br/>→ Höhere Sensitivität<br/>→ Mehr FP akzeptieren"]
Q1 -->|"FP kritisch<br/>(Unnötige OP)"| A2["Höherer Schwellenwert<br/>→ Höhere Spezifität<br/>→ Mehr FN akzeptieren"]
end
style A1 fill:#e3f2fd
style A2 fill:#fff3e0
Beispiel: Krebsdiagnose
Bei einem Test auf eine ernsthafte, aber behandelbare Krankheit wie Krebs:
- Hohe Sensitivität (TPR): Fast alle tatsächlichen Fälle werden erkannt
- Akzeptierte höhere FPR: Einige Gesunde werden fälschlich positiv getestet
Dies ist vertretbar, weil:
- Ein übersehener Krebsfall (FN) kann tödlich sein
- Ein falscher Alarm (FP) führt “nur” zu weiteren Tests
Optimalen Schwellenwert finden
from sklearn.metrics import roc_curve
import numpy as np
# ROC-Kurve berechnen
fpr, tpr, thresholds = roc_curve(target_test, target_proba)
# Youden's J-Statistik: Maximiert TPR - FPR
j_scores = tpr - fpr
optimal_idx = np.argmax(j_scores)
optimal_threshold = thresholds[optimal_idx]
print(f"Optimaler Schwellenwert: {optimal_threshold:.4f}")
print(f"TPR bei optimalem Schwellenwert: {tpr[optimal_idx]:.4f}")
print(f"FPR bei optimalem Schwellenwert: {fpr[optimal_idx]:.4f}")
Area Under the Curve (AUC)
Die AUC (Area Under the ROC Curve) fasst die Leistung eines Klassifikators in einer einzigen Zahl zusammen.
Interpretation
flowchart LR
subgraph auc_scale["AUC Interpretation"]
direction LR
A1["0.5<br/>Zufall"]
A2["0.6<br/>Schwach"]
A3["0.7<br/>Akzeptabel"]
A4["0.8<br/>Gut"]
A5["0.9<br/>Sehr gut"]
A6["1.0<br/>Perfekt"]
end
A1 --> A2 --> A3 --> A4 --> A5 --> A6
style A1 fill:#ffcdd2
style A2 fill:#fff9c4
style A3 fill:#e8f5e9
style A4 fill:#c8e6c9
style A5 fill:#a5d6a7
style A6 fill:#81c784
| AUC-Wert | Interpretation |
|---|---|
| 0.5 | Keine Unterscheidungsfähigkeit (Zufall) |
| 0.6 - 0.7 | Schwache Diskriminierung |
| 0.7 - 0.8 | Akzeptable Diskriminierung |
| 0.8 - 0.9 | Gute Diskriminierung |
| > 0.9 | Exzellente Diskriminierung |
Vorteile der AUC
- Schwellenwert-unabhängig: Bewertet die gesamte ROC-Kurve
- Vergleichbarkeit: Ermöglicht einfachen Modellvergleich
- Robust: Weniger anfällig für Klassenungleichgewichte als Accuracy
Implementierung
from sklearn.metrics import roc_auc_score
# AUC berechnen
auc = roc_auc_score(target_test, target_proba)
print(f"AUC: {auc:.4f}")
# Für Multi-Class
auc_ovr = roc_auc_score(target_test, target_proba_multi, multi_class='ovr')
print(f"AUC (One-vs-Rest): {auc_ovr:.4f}")
Modellvergleich mit AUC
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# Mehrere Modelle vergleichen
models = [
('Logistische Regression', model_lr_proba),
('Random Forest', model_rf_proba),
('XGBoost', model_xgb_proba)
]
plt.figure(figsize=(10, 8))
for name, target_proba in models:
fpr, tpr, _ = roc_curve(target_test, target_proba)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f'{name} (AUC = {roc_auc:.3f})')
plt.plot([0, 1], [0, 1], 'k--', label='Zufall')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC-Kurven Vergleich')
plt.legend()
plt.show()
Umgang mit unausgewogenen Klassen
[!WARNING] Geschäftsrisiko
Bei unausgewogenen Klassen führt die falsche Metrik oft zu teuren Fehlentscheidungen im Betrieb.
[!TIP] Metrik nach Kostenmodell wählen
Wenn False Negatives kritisch sind, Recall priorisieren; wenn False Positives teuer sind, Precision priorisieren.
Bei unausgewogenen Datensätzen (Imbalanced Classification) sind Standard-Metriken oft irreführend. Die richtige Metrikauswahl ist entscheidend.
Entscheidungsbaum zur Metrikauswahl
flowchart TD
Start["Binäre Klassifikation<br/>mit unausgewogenen Daten"]
Q1{Was ist das<br/>Hauptziel?}
Q1 -->|"Positive Klasse<br/>erkennen"| Q2{Welche Fehler<br/>sind kritischer?}
Q1 -->|"Beide Klassen<br/>korrekt"| A1["F1-Score<br/>oder AUC"]
Q1 -->|"Ranking/<br/>Sortierung"| A2["AUC-ROC"]
Q2 -->|"False Negatives<br/>(Übersehen)"| A3["Recall<br/>optimieren"]
Q2 -->|"False Positives<br/>(Fehlalarm)"| A4["Precision<br/>optimieren"]
Q2 -->|"Beide<br/>gleich wichtig"| A5["F1-Score"]
style A1 fill:#e3f2fd
style A2 fill:#e3f2fd
style A3 fill:#e8f5e9
style A4 fill:#fff3e0
style A5 fill:#f3e5f5
Empfehlungen nach Anwendungsfall
| Anwendungsfall | Empfohlene Metrik | Begründung |
|---|---|---|
| Medizinische Diagnose | Recall + Spezifität | Kranke nicht übersehen |
| Spam-Erkennung | Precision + F1 | Normale E-Mails nicht blockieren |
| Betrugserkennung | Recall + AUC | Betrug nicht durchlassen |
| Qualitätskontrolle | Precision + Recall | Balance je nach Kosten |
| Kreditwürdigkeit | AUC + F1 | Ranking und Gesamtleistung |
Precision-Recall-Kurve als Alternative
Bei stark unausgewogenen Daten kann die Precision-Recall-Kurve informativer sein als die ROC-Kurve:
from sklearn.metrics import precision_recall_curve, average_precision_score
import matplotlib.pyplot as plt
# Precision-Recall-Kurve
precision, recall, thresholds = precision_recall_curve(target_test, target_proba)
ap = average_precision_score(target_test, target_proba)
plt.figure(figsize=(8, 6))
plt.plot(recall, precision, label=f'AP = {ap:.3f}')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall-Kurve')
plt.legend()
plt.show()
Zusammenfassung: Metrik-Übersicht
[!SUCCESS] Mindeststandard
Neben Accuracy immer mindestens Precision, Recall, F1 und eine klassenbezogene Auswertung berichten.
flowchart TB
subgraph overview["<b>Klassifikationsmetriken"]
subgraph basic["<b>Basis-Metriken"]
CM["<b>Confusion Matrix<br/>(TP, TN, FP, FN)"]
ACC["<b>Accuracy<br/>Gesamtgenauigkeit"]
PRE["<b>Precision<br/>Relevanz der Positiven"]
REC["<b>Recall<br/>Vollständigkeit der Erkennung"]
end
subgraph combined["<b>Kombinierte Metriken"]
F1["<b>F1-Score<br/>Harmonisches Mittel P & R"]
KAP["<b>Cohen's Kappa<br/>Zufallskorrigierte Accuracy"]
end
subgraph threshold["<b>Schwellenwert-basiert"]
ROC["<b>ROC-Kurve<br/>TPR vs. FPR"]
AUC["<b>AUC<br/>Fläche unter ROC"]
PRC["<b>PR-Kurve<br/>Precision vs. Recall"]
end
CM --> basic
basic --> combined
basic --> threshold
end
Quick Reference: Wann welche Metrik?
| Situation | Empfohlene Metrik(en) |
|---|---|
| Ausgewogene Klassen | Accuracy, F1-Score |
| Unausgewogene Klassen | F1-Score, AUC, Cohen’s Kappa |
| Kosten unterschiedlich | Precision oder Recall (je nach Kosten) |
| Modellvergleich | AUC |
| Schwellenwert-Optimierung | ROC-Kurve mit Youden’s J |
| Sehr seltene positive Klasse | PR-Kurve, Average Precision |
Komplettes Evaluations-Template
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
cohen_kappa_score, roc_auc_score, classification_report,
confusion_matrix, ConfusionMatrixDisplay
)
import matplotlib.pyplot as plt
def evaluate_classifier(target_true, target_pred, target_proba=None, class_names=None):
"""
Umfassende Evaluation eines Klassifikationsmodells.
"""
print("=" * 50)
print("KLASSIFIKATIONS-EVALUATION")
print("=" * 50)
# Basis-Metriken
print(f"\nAccuracy: {accuracy_score(target_true, target_pred):.4f}")
print(f"Precision: {precision_score(target_true, target_pred, average='weighted'):.4f}")
print(f"Recall: {recall_score(target_true, target_pred, average='weighted'):.4f}")
print(f"F1-Score: {f1_score(target_true, target_pred, average='weighted'):.4f}")
print(f"Cohen's Kappa: {cohen_kappa_score(target_true, target_pred):.4f}")
# AUC (falls Wahrscheinlichkeiten verfügbar)
if target_proba is not None:
if len(target_proba.shape) == 1 or target_proba.shape[1] == 2:
proba = target_proba[:, 1] if len(target_proba.shape) > 1 else target_proba
print(f"AUC-ROC: {roc_auc_score(target_true, proba):.4f}")
# Classification Report
print("\n" + "-" * 50)
print("Classification Report:")
print("-" * 50)
print(classification_report(target_true, target_pred, target_names=class_names))
# Confusion Matrix visualisieren
fig, ax = plt.subplots(figsize=(8, 6))
ConfusionMatrixDisplay.from_predictions(
target_true, target_pred,
display_labels=class_names,
cmap='Blues',
ax=ax
)
plt.title('Confusion Matrix')
plt.tight_layout()
plt.show()
# Verwendung
evaluate_classifier(target_test, target_pred, target_proba, class_names=['Negativ', 'Positiv'])
Weiterführende Themen
- Cross-Validation: Robustere Schätzung der Metriken durch mehrfache Splits
- Learning Curves: Diagnose von Over-/Underfitting
- Calibration: Zuverlässigkeit der Wahrscheinlichkeitsvorhersagen
- Cost-Sensitive Learning: Berücksichtigung unterschiedlicher Fehlerkosten
Referenzen:
- scikit-learn Dokumentation: Classification Metrics
- StatQuest: Confusion Matrix, ROC and AUC
Abgrenzung zu verwandten Dokumenten
| Thema | Abgrenzung |
|---|---|
| Bewertung: Regression | Klassifikations-Metriken fuer kategoriale Vorhersagen; Regressions-Metriken fuer kontinuierliche Werte |
| Overfitting | Klassifikations-Metriken quantifizieren Vorhersageguete; Overfitting erkennt man an der Train-Test-Diskrepanz |
| Cross-Validation | Cross-Validation ist die Evaluierungsmethodik; Klassifikations-Metriken sind die Messgroessen dabei |
Version: 1.0
Stand: Januar 2026
Kurs: Machine Learning. Verstehen. Anwenden. Gestalten.