Der Machine Learning Workflow
Der systematische Prozess von der Problemstellung bis zur produktiven Anwendung
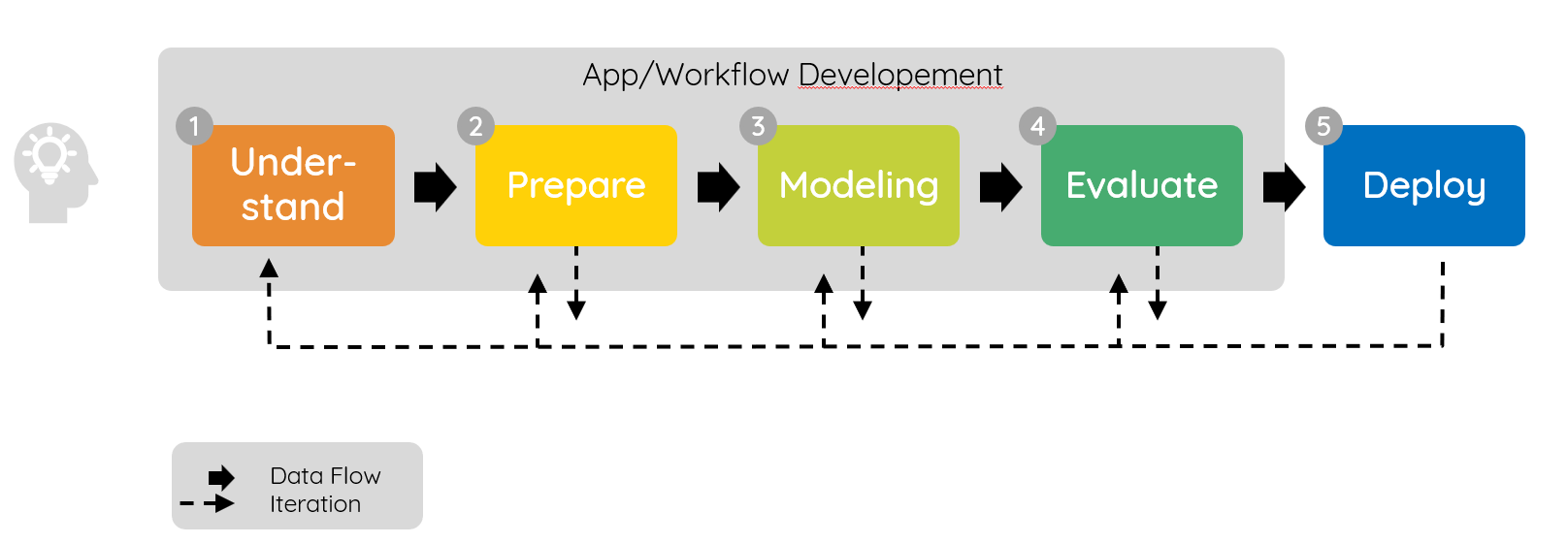
Fünf Phasen: Understand, Prepare, Modeling, Evaluate und Deploy
Inhaltsverzeichnis
- 1. Understand – Das Problem verstehen
- 2. Prepare – Daten aufbereiten
- 3. Modeling – Modell entwickeln
- 4. Evaluate – Modell bewerten
- 5. Deploy – Modell bereitstellen
- Der iterative Charakter
- Abgrenzung zu verwandten Dokumenten
Der Machine-Learning-Workflow beschreibt den systematischen Prozess von der ersten Problemstellung bis zur produktiven Anwendung eines ML-Modells. Die folgenden fünf Phasen bilden das Fundament jedes erfolgreichen ML-Projekts.
1. Understand – Das Problem verstehen
Die erste Phase bildet das Fundament für den gesamten ML-Workflow. Hier geht es darum, das Geschäftsproblem vollständig zu erfassen und in eine maschinell lösbare Aufgabe zu übersetzen.
Zentrale Fragen dieser Phase sind: Welches Problem soll gelöst werden? Welche Daten stehen zur Verfügung? Wie sieht Erfolg aus und wie wird er gemessen? Ohne ein klares Verständnis des Problems riskiert man, ein technisch perfektes Modell zu bauen, das am eigentlichen Bedarf vorbeigeht.
Diese Phase umfasst mehrere Teilschritte: Problem verstehen, Datensammlung und -integration aus verschiedenen Quellen, explorative Datenanalyse (EDA) zur Erkennung von Mustern und Besonderheiten.
In dieser Phase werden auch die Erfolgskriterien definiert – sowohl aus geschäftlicher Sicht (z.B. Kosteneinsparung, Zeitgewinn) als auch aus technischer Perspektive (z.B. Mindest-Accuracy, maximale Latenz).
2. Prepare – Daten aufbereiten
Die Datenaufbereitung ist häufig die zeitaufwändigste Phase eines ML-Projekts. Rohdaten sind selten direkt für das Training geeignet – sie enthalten fehlende Werte, Ausreißer, inkonsistente Formate oder irrelevante Informationen.
Diese Phase umfasst mehrere Teilschritte: Datenbereinigung (Handling von Missing Values, Duplikaten, Ausreißern), Skalierung von Daten mit unterschiedlichen Wertebereichen, Feature Engineering zur Erstellung aussagekräftiger Merkmale sowie die Aufteilung in Trainings-, Validierungs- und Testdaten.
Die Qualität der Datenaufbereitung bestimmt maßgeblich die Qualität des späteren Modells – nach dem Prinzip Garbage in, garbage out.
3. Modeling – Modell entwickeln
In der Modeling-Phase wird der passende Algorithmus ausgewählt und das Modell trainiert. Die Wahl des Algorithmus hängt von mehreren Faktoren ab: Art des Problems (Regression, Klassifikation, Clustering), Datenmenge und -struktur, Anforderungen an Interpretierbarkeit sowie verfügbare Rechenressourcen.
Typische Schritte sind: Auswahl geeigneter Algorithmen basierend auf dem Problemtyp, Training verschiedener Modelle mit den vorbereiteten Daten, Hyperparameter-Tuning zur Optimierung der Modellleistung und Vergleich verschiedener Ansätze.
Es empfiehlt sich, mit einfachen Baseline-Modellen zu beginnen und die Komplexität schrittweise zu erhöhen. Ein einfaches, interpretierbares Modell ist oft wertvoller als ein komplexes Black-Box-Modell mit marginal besserer Performance.
4. Evaluate – Modell bewerten
Die Evaluationsphase prüft, ob das trainierte Modell die definierten Anforderungen erfüllt. Dabei werden verschiedene Metriken herangezogen, die zum Problemtyp passen müssen.
Klassifikationsaufgaben nutzen Accuracy, Precision, Recall, F1-Score und die Confusion Matrix. Für Regressionsaufgaben sind MSE, RMSE und R² relevant. Bei unbalancierten Datensätzen sind ROC-AUC und PR-AUC besonders aussagekräftig.
Wichtig ist die Bewertung auf ungesehenen Testdaten, um Overfitting zu erkennen. Cross-Validation hilft dabei, robuste Schätzungen der Modellleistung zu erhalten. Erfüllt das Modell die Anforderungen nicht, führen die gestrichelten Pfeile zurück zu früheren Phasen – sei es zur Datenaufbereitung, zum Modeling oder sogar zur Problemdefinition.
5. Deploy – Modell bereitstellen
Die Deployment-Phase überführt das validierte Modell in eine produktive Umgebung, wo es echte Vorhersagen für Endanwender liefert. Dieser Schritt erfordert oft zusätzliche Arbeit jenseits des reinen ML-Codes.
Aspekte dieser Phase umfassen: Integration in bestehende Systeme und Workflows, Skalierung für den Produktionsbetrieb, Monitoring der Modellleistung über Zeit, Versionierung und Reproduzierbarkeit sowie Strategien für Modell-Updates.
Ein deployed Modell ist kein Endpunkt, sondern der Beginn eines kontinuierlichen Zyklus. Die gestrichelten Rückpfeile im Diagramm verdeutlichen: Wenn sich Daten oder Anforderungen ändern (Data Drift, Concept Drift), muss der Prozess erneut durchlaufen werden – von der Problemanalyse bis zur erneuten Bereitstellung.
Der iterative Charakter
Die gestrichelten Pfeile im Diagramm sind kein Zeichen von Fehlern, sondern ein wesentliches Merkmal erfolgreicher ML-Projekte. Machine Learning ist ein iterativer Prozess: Erkenntnisse aus späteren Phasen führen regelmäßig zu Verbesserungen in früheren Schritten.
Ein Modell mit unbefriedigender Performance kann auf Probleme in der Datenaufbereitung hinweisen. Feedback aus dem Produktivbetrieb kann neue Feature-Ideen liefern. Veränderte Geschäftsanforderungen erfordern eine Neubewertung des ursprünglichen Problems. Diese Flexibilität und Bereitschaft zur Iteration unterscheidet erfolgreiche ML-Projekte von gescheiterten.
Abgrenzung zu verwandten Dokumenten
| Thema | Abgrenzung |
|---|---|
| ML Grundlagen | Grundlagen erklaeren was ML ist; der Workflow zeigt wie Projekte phasenweise durchgefuehrt werden |
| Workflow-Design (Pipelines) | ML-Workflow beschreibt die 5 Phasen uebergeordnet; Workflow-Design konkretisiert technische Umsetzung mit scikit-learn Pipelines |
| Hyperparameter-Tuning | Der Workflow rahmt alle Phasen ein; Hyperparameter-Tuning ist eine spezialisierte Optimierungstechnik in Phase 3 |
Version: 1.0
Stand: Januar 2026
Kurs: Machine Learning. Verstehen. Anwenden. Gestalten.