Tokenizing & Chunking
Text-Preprocessing für LLMs: Tokenization-Strategien und Chunking-Methoden für RAG
Inhaltsverzeichnis
- Tokenizer-, Chunking- & Strategieauswahl
- Beispiel
- Parameter- und Strategieauswahl
- Chunking-Strategien im Detail
- Tokenizer-Typen im Vergleich
- Best Practices
- Evaluation & Monitoring
- Implementierungs-Beispiel (LangChain)
- Fazit
Die Textverarbeitung in LLM-Systemen steht und fällt oft mit drei Entscheidungen: Welcher Tokenizer wird verwendet, wie groß sind die Chunks und nach welcher Logik werden sie gebildet. Auf dem Papier wirken diese Parameter technisch und nachgeordnet. In RAG- oder Analyseaufgaben entscheiden sie jedoch oft darüber, ob relevante Informationen überhaupt wiedergefunden werden.
In der Praxis zeigt sich ein typisches Muster: Wenn Antworten unpräzise, unvollständig oder instabil sind, wird zunächst das Modell verdächtigt. Häufig liegt das Problem jedoch früher in der Pipeline. Chunks sind zu klein, Grenzen fallen ungünstig, oder Überlappungen erzeugen unnötiges Rauschen. Genau deshalb lohnt es sich, Tokenizing und Chunking nicht als reine Vorverarbeitung zu behandeln.
Tokenizer-, Chunking- & Strategieauswahl
Dokumenttypen
| Dokumenttyp | Tokenizer | Chunk-Größe | Überlappung | Chunking-Strategie | Begründung |
|---|---|---|---|---|---|
| Lange Texte | SentencePiece oder BPE | 512–1024 Tokens | 20–30% | Semantisches & embeddingbasiertes Chunking | Diese Tokenizer zerlegen den Text in kleinere, semantisch sinnvolle Einheiten. Größere Chunks helfen, den Kontext beizubehalten und logische Einheiten in dichten Texten zu bewahren. |
| Mittel-lange Texte | WordPiece | 256–512 Tokens | 10–20% | Semantisches Chunking | WordPiece verarbeitet gemischte Sprache gut. Semantisches Chunking fasst narrative und strukturierte Abschnitte optimal zusammen, ohne den Text zu stark zu fragmentieren. |
| Kurze Texte | Whitespace-/Symbol-basierte Tokenizer | 50–200 Tokens | 0–5% | Rekursives Zeichen-Chucking | Kurze, oft stark strukturierte Texte profitieren von kleinen Chunks. Rekursives Zeichen-Chucking kann helfen, bei fehlenden klaren Grenzen die Struktur zu wahren. |
| Code & Technische Dokumente | Whitespace- oder benutzerdefinierte symbolbasierte Tokenizer | Ca. 256 Tokens (pro Funktion/Absatz) | Variabel (minimale Überlappung) | Agentisches Chunking | Die strukturelle Integrität ist entscheidend, um die Semantik des Codes zu erhalten. Agentisches Chunking berücksichtigt funktionale Zusammenhänge und stellt die Intaktheit der Blöcke sicher. |
Anwendungsszenarien
| Szenario | Ziel | Empfohlenes Chunking | Strategie | Begründung |
|---|---|---|---|---|
| Antworten auf Fragen | Exakte Extraktion relevanter Passagen | 512 Tokens mit hoher Überlappung (30–50%) | Kombination aus semantischem und embeddingbasiertem Chunking | Hohe Überlappung stellt sicher, dass der Kontext zwischen den Chunks nicht verloren geht. Semantische Grenzen und embeddingbasierte Analysen erfassen relevante Abschnitte präzise. |
| Zusammenfassungen | Verdichtung des Inhalts bei Beibehaltung der Kernaussagen | 256 Tokens mit moderater Überlappung (10–20%) | Semantisches Chunking | Semantisches Chunking bewahrt komplette Sinnabschnitte, sodass die Kernaussagen klar extrahiert werden können, ohne den Kontext zu verlieren. |
| Informationsretrieval (RAG) | Effiziente Auffindbarkeit relevanter Abschnitte | 256–512 Tokens mit moderater Überlappung (10–20%) | Embeddingbasiertes Chunking | Embeddingbasiertes Chunking gruppiert semantisch verwandte Inhalte. So werden relevante Informationen leichter auffindbar und retrieval-technisch optimal aufbereitet. |
| Named Entity Recognition (NER) | Identifikation wichtiger Entitäten | Ca. 256 Tokens an Satzgrenzen, minimale Überlappung (5–15%) | Semantisches Chunking (ggf. kombiniert mit embeddingbasierten Ansätzen) | Durch an Satzgrenzen ausgerichtete Chunks wird vermieden, dass Entitäten aufgespalten werden. Eine embeddingbasierte Analyse kann zusätzlich helfen, zusammengehörige Entitäten zu erfassen. |
| Textklassifikation | Zuweisung von Labels zu Dokumenten oder Abschnitten | Ganze Dokumente oder 512 Tokens, wenig bis keine Überlappung | Semantisches Chunking (optional mit reduzierter Granularität) | Gröbere Unterteilungen verhindern Rauschen, während semantische Einheiten erhalten bleiben, die für die Klassifikation relevant sind. |
| Code-Kommentierung/Erklärung | Verständnis und Erklärung von Codeabschnitten | Pro Funktion/Modul, Überlappung nur bei Bedarf | Agentisches Chunking | Agentisches Chunking berücksichtigt syntaktische und semantische Aspekte des Codes. So bleiben logische Zusammenhänge, wie Funktionsdefinitionen, erhalten und können optimal erklärt werden. |
[!NOTE] Pilotphase
Vor einer konkreten Implementierung lohnt sich eine kurze Pilotphase mit echten Dokumenten. Häufig reichen schon zwei oder drei Varianten, um zu sehen, ob ein Setup eher Kontext erhält oder eher Rauschen produziert.
Beispiel
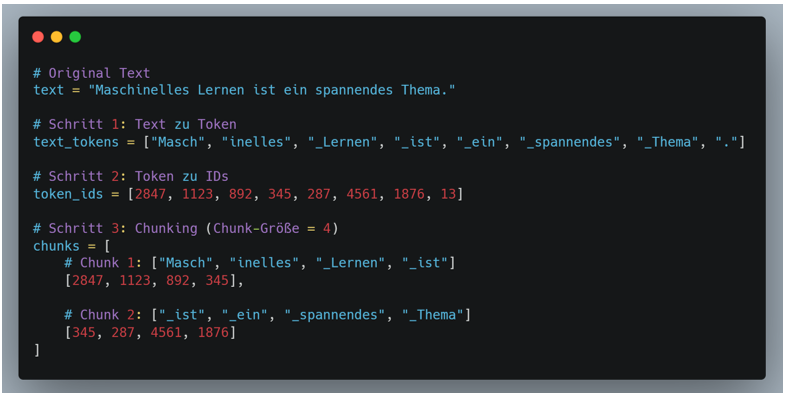
- Tokenizing:
- Zerlegt Text in kleinste Einheiten (Token)
- Diese Token werden in Zahlen (IDs) umgewandelt
- Ein Token kann ein Wort, Teil eines Wortes oder ein Satzzeichen sein
- Chunking:
- Gruppiert die Token in verarbeitbare Blöcke
- Beispiel: Bei max. 4096 Token pro Anfrage werden längere Texte in Chunks aufgeteilt
- Jeder Chunk behält dabei genug Überlappung (hier 1) zum vorherigen Chunk für Kontexterhalt
- Zusammenspiel:
- Text wird erst tokenisiert (in kleinste Einheiten zerlegt)
- Die Token werden dann in Chunks gruppiert (für Verarbeitung)
- Chunks werden nacheinander verarbeitet
- LLM behält Kontext zwischen Chunks durch Überlappungen
Parameter- und Strategieauswahl
- Tokenizer-Auswahl:
- SentencePiece/BPE sind ideal für lange, unstrukturierte Texte, da sie feine Subworteinheiten erzeugen und dabei semantische Bedeutung beibehalten.
- WordPiece ist optimal für hybride Texte, in denen technische sowie allgemeine Sprache vorkommen.
- Whitespace-/Symbol-basierte Tokenizer (oder speziell angepasste Tokenizer für Code) gewährleisten, dass die Struktur, beispielsweise in kurzen Texten oder Quellcode, erhalten bleibt.
- Chunk-Größe und Überlappung:
- Die Chunk-Größe wird so gewählt, dass jeweils eine komplette logische Einheit erfasst wird. Längere Texte benötigen größere Chunks, während bei kurzen Texten kleinere, präzisere Segmente ausreichend sind.
- Überlappung hilft dabei, Kontextinformationen am Rand der Chunks nicht zu verlieren. Für komplexe Aufgaben (wie präzise Fragebeantwortung) ist eine höhere Überlappung vorteilhaft, wohingegen bei Aufgaben wie Klassifikation geringere Überlappungen ausreichend sind.
- Zusätzliche Chunking-Strategien:
- Semantisches Chunking zielt darauf ab, thematisch und inhaltlich zusammenhängende Abschnitte zu bilden.
- Rekursives Zeichen-Chucking eignet sich, wenn keine klaren sprachlichen Grenzen vorliegen oder bei sehr strukturierten, kurzen Dokumenten.
- Embeddingbasiertes Chunking nutzt Ähnlichkeiten im Einbettungsraum, um semantisch verwandte Inhalte zu gruppieren, was insbesondere bei Retrieval-Aufgaben nützlich ist.
- Agentisches Chunking verwendet agentenbasierte Verfahren, um logische und syntaktische Zusammenhänge zu identifizieren – ein Ansatz, der besonders bei Code und technischen Dokumenten Vorteile bietet.
- Praktische Rahmenbedingungen:
- Speicherverbrauch und Verarbeitungsgeschwindigkeit lassen sich durch Anpassung der Chunk-Größe steuern. Kleinere Chunks reduzieren den Speicherbedarf und beschleunigen die Verarbeitung, was vor allem bei großen Datenmengen von Bedeutung ist.
- Kosten können durch die Optimierung der Überlappung minimiert werden. Eine zu hohe Überlappung erhöht Redundanzen und Rechenaufwand, sodass hier ein ausgewogenes Verhältnis gefunden werden muss.
Aus Kurssicht ist vor allem eine Erfahrung wichtig: Es gibt selten eine universell richtige Chunk-Größe. Gute Werte hängen stark davon ab, ob Absätze, Abschnitte, Funktionsblöcke oder stark strukturierte Datensätze verarbeitet werden. Wer ohne Testdaten sofort auf “Best Practices” vertraut, optimiert oft am eigentlichen Problem vorbei.
[!NOTE] Praxistest
Die Eignung von Chunk-Größen und -Strategien zeigt sich am zuverlässigsten mit echten Daten, nicht mit Beispieltexten. Relevant sind dabei vor allem Abrufgenauigkeit, Antwortqualität und die Frage, ob wichtige Informationen an Chunk-Grenzen verloren gehen.
Chunking-Strategien im Detail
Verschiedene Chunking-Strategien haben spezifische Vor- und Nachteile, die je nach Anwendung berücksichtigt werden sollten.
Zeichenbasiertes Chunking
- Einfach: Text wird nach fester Zeichenanzahl geteilt
- Nachteile: Kann Wörter oder Sätze mitten durchschneiden
- Anwendung: Selten empfohlen, nur für sehr einfache Fälle
Rekursives Zeichen-Chunking
- Vorgehen: Versucht zunächst an Absatzgrenzen zu trennen, dann an Sätzen, schließlich an Wörtern
- Vorteile: Erhält mehr strukturelle Integrität als einfaches Zeichen-Chunking
- Anwendung: Standard für viele Texttypen
Dokumentbasiertes Chunking
- Vorgehen: Nutzt dokumentspezifische Struktur (z.B. Markdown-Header, HTML-Tags)
- Vorteile: Semantisch sinnvolle Grenzen
- Anwendung: Strukturierte Dokumente, technische Dokumentation
Semantisches Chunking
- Vorgehen: Analysiert semantische Ähnlichkeit zwischen Sätzen
- Vorteile: Hält zusammenhängende Inhalte zusammen
- Nachteile: Rechenintensiver
- Anwendung: Hochwertige RAG-Systeme
Embeddingbasiertes Chunking
- Vorgehen: Nutzt Embeddings um semantisch ähnliche Abschnitte zu identifizieren
- Vorteile: Sehr genaue semantische Gruppierung
- Nachteile: Hoher Rechenaufwand
- Anwendung: Retrieval-optimierte Systeme
Agentisches Chunking
- Vorgehen: KI-Agent analysiert Text und entscheidet über Chunk-Grenzen
- Vorteile: Adaptiv, kontextabhängig
- Nachteile: Komplex, teuer
- Anwendung: Hochspezialisierte Anwendungen, Code-Analyse
Tokenizer-Typen im Vergleich
Byte-Pair Encoding (BPE)
- Prinzip: Häufig auftretende Zeichenpaare werden iterativ zusammengefasst
- Vorteile:
- Kompaktes Vokabular
- Guter Umgang mit seltenen Wörtern
- Nachteile:
- Training erforderlich
- Verwendung: GPT-Modelle, viele Transformer
WordPiece
- Prinzip: Ähnlich wie BPE, optimiert auf Wahrscheinlichkeitsmaximierung
- Vorteile:
- Effizient für mehrsprachige Modelle
- Gute Generalisierung
- Nachteile:
- Komplexere Implementation
- Verwendung: BERT, DistilBERT
SentencePiece
- Prinzip: Behandelt Text als Rohdaten ohne Whitespace-Annahmen
- Vorteile:
- Language-agnostic (funktioniert für alle Sprachen)
- Keine Vorverarbeitung nötig
- Nachteile:
- Etwas langsamer
- Verwendung: T5, XLNet
Whitespace/Symbol-basierte Tokenizer
- Prinzip: Trennung an Leerzeichen und Satzzeichen
- Vorteile:
- Sehr einfach
- Schnell
- Gut für Code
- Nachteile:
- Großes Vokabular
- Probleme mit zusammengesetzten Wörtern
- Verwendung: Einfache Anwendungen, Code-Analyse
Best Practices
Chunk-Größe wählen
- Kleine Chunks (128-256 Tokens):
- Präzises Retrieval
- Höhere Kosten (mehr Chunks)
- Risiko: Kontextverlust
- Mittlere Chunks (256-512 Tokens):
- Guter Kompromiss
- Standard für die meisten Anwendungen
- Große Chunks (512-1024 Tokens):
- Mehr Kontext
- Weniger Chunks
- Risiko: Irrelevante Informationen
Überlappung optimieren
- Keine Überlappung (0%): Nur wenn Chunks völlig unabhängig sind
- Kleine Überlappung (5-10%): Strukturierte Dokumente
- Moderate Überlappung (10-20%): Standard für RAG
- Hohe Überlappung (30-50%): Wenn Kontext kritisch ist (Q&A)
Strategie-Auswahl
flowchart TD
START([Text analysieren]) --> Q1{Ist der Text<br>strukturiert?}
Q1 -->|JA| DOK[Dokumentbasiertes<br>Chunking]
Q1 -->|NEIN| Q2{Ist semantische<br>Kohärenz wichtig?}
Q2 -->|NEIN| ZEICHEN[Einfaches<br>Zeichenbasiertes Chunking]
Q2 -->|JA| Q3{Ist Rechenleistung<br>verfügbar?}
Q3 -->|JA| EMBED[Embeddingbasiertes oder<br>Semantisches Chunking]
Q3 -->|NEIN| REKURSIV[Rekursives<br>Zeichen-Chunking]
START --> Q4{Ist es Code?}
Q4 -->|JA| AGENT[Agentisches oder<br>AST-basiertes Chunking]
style START fill:#e3f2fd,stroke:#1976d2
style DOK fill:#c8e6c9,stroke:#388e3c
style ZEICHEN fill:#c8e6c9,stroke:#388e3c
style EMBED fill:#c8e6c9,stroke:#388e3c
style REKURSIV fill:#c8e6c9,stroke:#388e3c
style AGENT fill:#c8e6c9,stroke:#388e3c
Evaluation & Monitoring
Metriken für Chunking-Qualität
- Retrieval Precision: Anteil relevanter Chunks in Top-K Ergebnissen
- Retrieval Recall: Anteil gefundener relevanter Chunks
- Context Preservation: Wird wichtiger Kontext über Chunk-Grenzen hinweg erhalten?
- Chunk Size Distribution: Sind die Chunks gleichmäßig groß?
A/B Testing
Sinnvoll ist der Vergleich mehrerer Konfigurationen:
- Chunk-Größe: 256 vs. 512 Tokens
- Überlappung: 10% vs. 20%
- Strategie: Rekursiv vs. Semantisch
Geeignete Messgrößen sind:
- Antwortqualität (manuell oder mit LLM-as-Judge)
- Retrieval-Geschwindigkeit
- Kosten (API-Calls, Compute)
Implementierungs-Beispiel (LangChain)
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Rekursives Zeichen-Chunking mit LangChain
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # Chunk-Größe in Zeichen
chunk_overlap=50, # Überlappung in Zeichen
length_function=len,
separators=["\n\n", "\n", " ", ""] # Hierarchie der Trennzeichen
)
chunks = text_splitter.split_text(document_text)
Wichtig: chunk_size bezieht sich hier auf Zeichen, nicht Tokens! Für Token-basiertes Chunking:
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size=512, # Chunk-Größe in Tokens
chunk_overlap=50 # Überlappung in Tokens
)
chunks = text_splitter.split_text(document_text)
Fazit
Die Wahl der richtigen Kombination aus Tokenizer, Chunk-Größe und Chunking-Strategie ist entscheidend für die Qualität einer NLP-Anwendung:
- Dokumenttyp bestimmt Tokenizer: Lange Texte → BPE/SentencePiece, Code → Whitespace/Symbol
- Anwendung bestimmt Chunk-Größe: Q&A → größer mit Überlappung, Klassifikation → größer ohne Überlappung
- Strategie folgt Anforderungen: Semantik wichtig → Semantisches/Embedding-basiert, Struktur wichtig → Dokumentbasiert
- Tests mit echten Daten: A/B-Tests sind hier deutlich aussagekräftiger als Beispieltexte
Weiterführende Ressourcen:
Abgrenzung zu verwandten Dokumenten
| Dokument | Frage |
|---|---|
| Embeddings | Wie werden die vorbereiteten Textstücke später semantisch repräsentiert? |
| RAG-Konzepte | Wie wirken Chunking-Entscheidungen auf Retrieval und Antwortqualität? |
| Transformer-Architektur | Warum spielen Token überhaupt eine so zentrale Rolle für Sprachmodelle? |
Version: 1.1
Stand: Januar 2026
Kurs: Generative KI. Verstehen. Anwenden. Gestalten.