Transformer Architektur
Deep Dive in Transformer-Modelle: Attention, Encoder-Decoder und moderne Varianten
Inhaltsverzeichnis
- Was ist ein Transformer?
- Die Grundidee
- Wie funktioniert das technisch?
- Drei Haupttypen von Transformern
- Warum sind Transformer so revolutionär?
- Top 10 Post-Transformer
Was ist ein Transformer?
Stellen wir uns vor, jemand liest einen Text und versucht ihn zu verstehen. Dabei schaut man nicht nur auf ein Wort nach dem anderen, sondern das Gehirn verbindet alle Wörter miteinander - manche sind wichtiger für das Verständnis als andere.
Ein Transformer macht genau das: Es ist ein Computer-Programm, das Texte “liest” und dabei automatisch erkennt, welche Wörter zusammengehören und wichtig sind.
Die Grundidee
Nehmen wir den Satz: „Der Hund bellt laut.“
-
Ein Mensch versteht sofort: „Hund“ ist das Subjekt der Handlung
-
„bellt“ ist das Verb und wird durch „laut“ näher beschrieben
-
Das Wort „Der“ gehört grammatikalisch zu „Hund“, ist aber weniger wichtig für die Bedeutung von „bellt“
Ein Transformer-Modell erkennt diese Zusammenhänge über den Self-Attention-Mechanismus:
Beim Verarbeiten von „bellt“ wird besonders auf „Hund“ und „laut“ geachtet, weil sie für die Bedeutung relevant sind.
„Der“ wird zwar berücksichtigt, erhält aber ein geringeres Gewicht.
Ein Transformer lernt diese Verbindungen automatisch durch Aufmerksamkeit:
- Es schaut sich alle Wörter gleichzeitig an
- Es berechnet, wie stark jedes Wort mit jedem anderen zusammenhängt
- Wichtige Verbindungen bekommen mehr “Aufmerksamkeit”
Wie funktioniert das technisch?
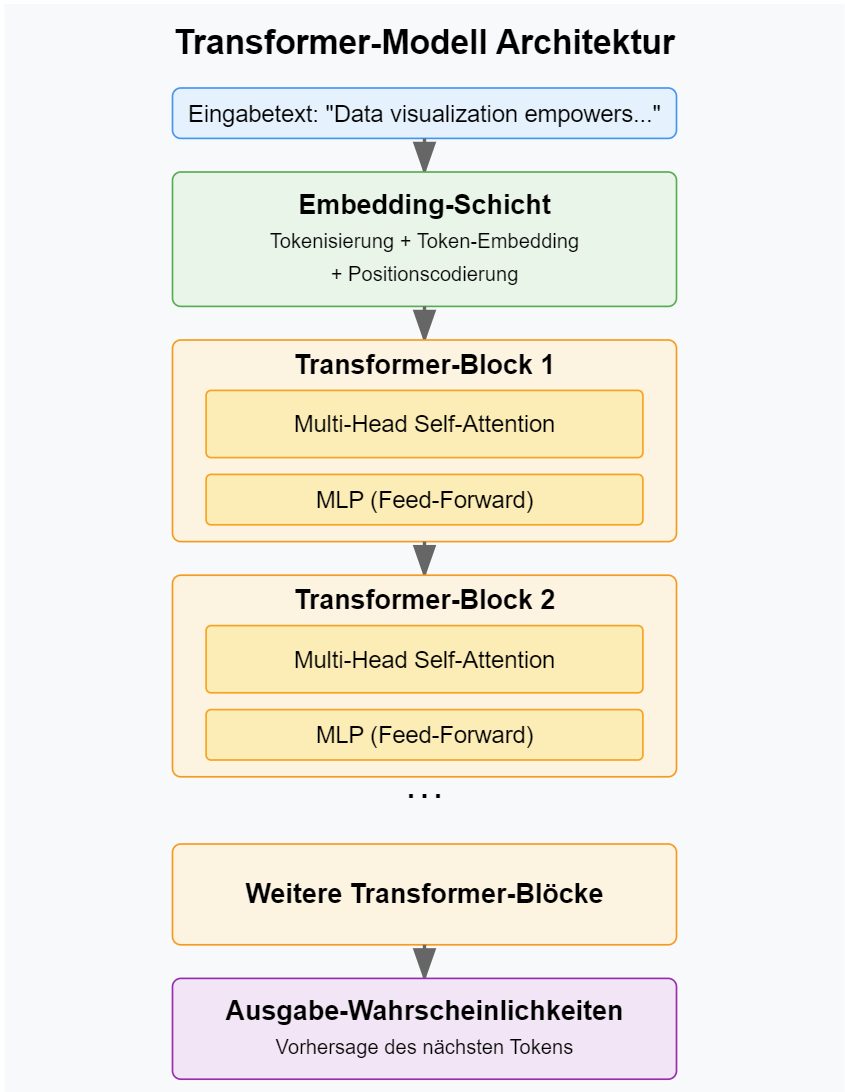
Wörter werden zu Zahlen → Embedding
- Computer können nur mit Zahlen arbeiten
- Jedes Wort wird in eine Liste von Zahlen umgewandelt (wie ein Fingerabdruck des Wortes)
[!NOTE] Weiterführender Verweis
Details siehe Skript: M08 - Embeddings
Position ist wichtig → Positional Encoding
- “Der Lehrer fragt den Schüler.” bedeutet etwas anderes als “Den Lehrer fragt der Schüler.”
- Der Transformer fügt jedem Wort eine “Positionsnummer” hinzu
Aufmerksamkeit berechnen → Self-Attention
Self-Attention ist ein Mechanismus, bei dem jedes Wort in einem Satz mit allen anderen Wörtern – einschließlich sich selbst – verglichen wird, um deren inhaltliche Ähnlichkeit oder Relevanz zu bestimmen. Diese Ähnlichkeitswerte helfen dem Modell dabei zu entscheiden, wie stark jedes Wort in die Repräsentation eines anderen Wortes einfließen soll.
Beispiel:
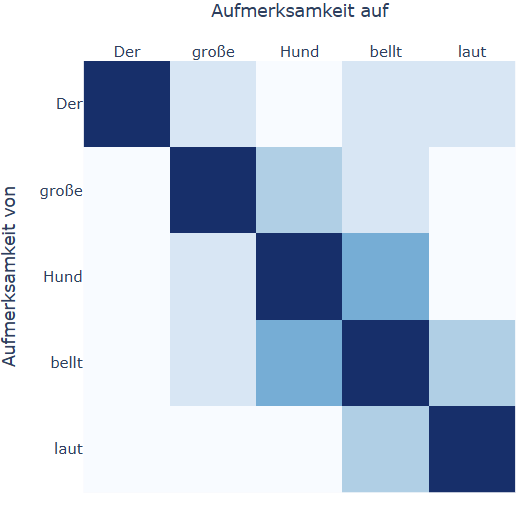
Im Satz „Der große Hund bellt laut“ wird das Wort „bellt“ mit allen anderen Wörtern verglichen:
-
Mit „Hund“ besteht eine starke inhaltliche Verbindung, da der Hund die Handlung ausführt.
-
„große“ beschreibt den Hund und ist damit indirekt relevant.
-
„laut“ beschreibt das Bellen und ist somit direkt mit „bellt“ verbunden.
-
„Der“ ist ein Artikel und hat weniger inhaltliches Gewicht.
Das Modell erkennt diese Zusammenhänge und gibt den relevanteren Wörtern (z. B. „Hund“ und „laut“) ein höheres Gewicht beim Kodieren von „bellt“. So entsteht eine kontextabhängige Repräsentation des Wortes „bellt“, die den Gesamtzusammenhang des Satzes besser widerspiegelt.
Um diese Aufmerksamkeit gezielt zu steuern, nutzt der Transformer für jedes Wort eine spezielle Fragetechnik. Dabei wird nicht nur geschaut, wie stark Wörter miteinander verbunden sind, sondern auch in welcher Rolle sie zueinander stehen.
Dazu stellt sich der Transformer bei jedem Wort drei zentrale Fragen:
- “Was suche ich?” – das ist die Query,
- “Was biete ich an?” – das ist der Key,
- “Was ist mein Inhalt?” – das ist der Value.
Beispiel mit dem Satz: “Der große Hund bellte laut.”
Das Wort “bellte” analysiert:
- Query (Was suche ich?): “Ich bin ein Verb und suche nach meinem Subjekt - wer macht die Handlung?”
- Key (Was biete ich an?): Von “Hund”: “Ich bin ein Substantiv und kann Subjekt sein!”
- Value (Was ist mein Inhalt?): Von “Hund”: “Ich bin ein Tier, männlich, mit der Eigenschaft ‘groß’”
Ergebnis: Der Transformer erkennt die starke Verbindung zwischen “Hund” und “bellte” und versteht: “Der Hund führt die Handlung des Bellens aus.”
Das passiert gleichzeitig für alle Wörter, sodass der Transformer alle wichtigen Beziehungen im Satz erkennt.
Mehrere “Köpfe” gleichzeitig → Multi-Head-Attention
Multi-Head-Attention bedeutet, dass der Transformer mehrere Self-Attention-Mechanismen gleichzeitig ausführt – mit unterschiedlichen Perspektiven (Köpfen).
Statt nur eine Sichtweise darauf zu berechnen, wie z. B. „bellt“ mit den anderen Wörtern zusammenhängt, berechnet das Modell mehrere parallele Sichtweisen, sogenannte „Heads“. Jeder Head hat eigene Query-, Key- und Value-Vektoren – mit unterschiedlichem Fokus.
Beispiel mit mehreren Köpfen:
Angenommen, es werden 3 Attention-Heads verwendet – dann könnten sie sich jeweils auf unterschiedliche Aspekte konzentrieren:
| Head | Möglicher Fokus |
|---|---|
| 1 | Wer tut etwas? – Beziehung zu „Hund“ |
| 2 | Wie wird etwas getan? – Beziehung zu „laut“ |
| 3 | Grammatikalische Struktur – z. B. Artikel |
Jeder Head rechnet eigene Attention-Gewichte und neue Repräsentationen für „bellt“.
Am Ende werden alle Ergebnisse zusammengeführt (konkatenieren und lineare Transformation), um eine reichhaltige, vielschichtige Repräsentation zu erzeugen.
Warum ist das sinnvoll?
Ein einzelner Attention-Mechanismus (ein „Kopf“) kann nur eine begrenzte Art von Beziehung gut erfassen. Mit Multi-Head-Attention lernt das Modell:
- verschiedene semantische Beziehungen gleichzeitig zu erkennen
- kontextuelle Nuancen besser zu verarbeiten
- feinere Unterscheidungen im Satzbau zu erfassen
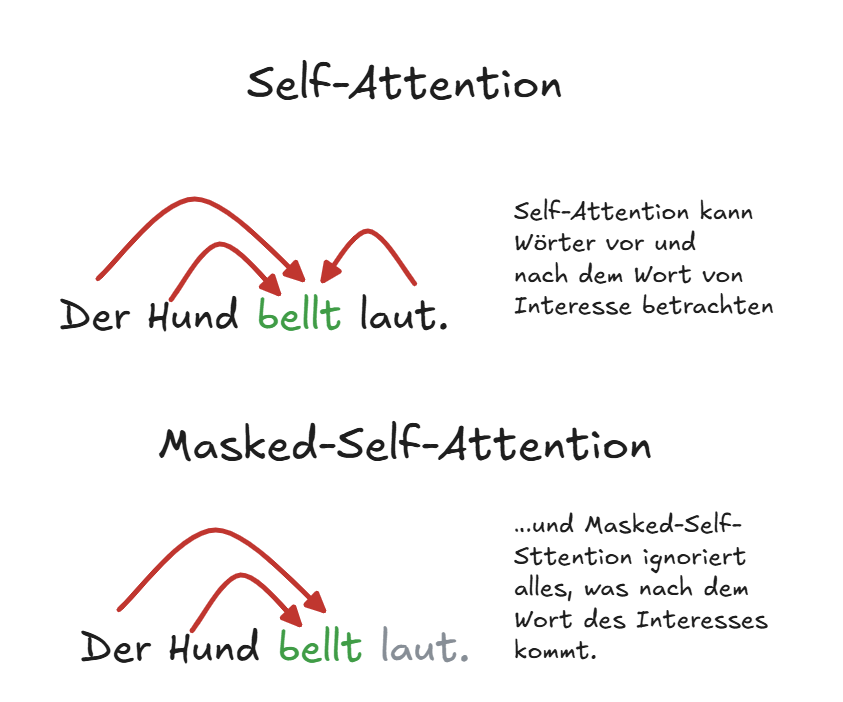
In die Zukunft schauen verboten → Masked-Self-Attention
Problem beim Text-Generieren:
Beim Generieren von Text (z. B. mit GPT) erzeugt das Modell ein Wort nach dem anderen.
Dabei soll es nur auf das schauen dürfen, was bereits gesagt wurde – nicht auf zukünftige Wörter, die es ja gerade erst selbst erzeugen soll!
Ohne Maske (normale Self-Attention):
Das Modell würde bei der Vorhersage von Wort n+1 schon sehen, welches Wort an Position n+2 oder n+3 kommt. Das wäre Schummeln, weil das Modell dann keine echte Vorhersage trifft, sondern aus dem bereits bekannten Ausgang „abliest“.
Mit Masked Self-Attention:
Das Modell wird gezwungen, zukünftige Wörter zu ignorieren, indem sie maskiert (ausgeblendet) werden.
Es sieht beim Vorhersagen nur den bisherigen Kontext, genau wie ein Mensch, der einen Satz schreibt.
Masked Self-Attention ist notwendig, damit ein Sprachmodell authentisch, Schritt für Schritt Text erzeugt, ohne zukünftige Wörter vorab zu kennen.
Es simuliert damit echtes Sprachverständnis im Schreibprozess.
Drei Haupttypen von Transformern
Transformer
Autoregressives Modell
Verstehen - Encoder-Only (wie BERT)
Fachbegriff: Bidirectional Encoder Representations
- Liest den ganzen Text und versteht ihn
- Kann Fragen zum Text beantworten
- Wie ein sehr guter Leser, der alles durchdenkt
Beispiel: “In welchem Jahr wurde Einstein geboren?” → Findet die Antwort im Text
Schreiben - Decoder-Only (wie ChatGPT)
Fachbegriff: Autoregressive Language Models
- Schreibt Text Wort für Wort
- Jedes neue Wort basiert auf allen vorherigen
- Wie ein Autor, der eine Geschichte weitererzählt
Beispiel: “Es war einmal…” → “Es war einmal ein kleiner Drache, der fliegen lernen wollte…”
Übersetzen - Encoder-Decoder (wie T5)
Fachbegriff: Sequence-to-Sequence Models
- Liest Input vollständig, dann schreibt Output
- Verbindet Verstehen und Schreiben
- Wie ein Übersetzer, der erst alles versteht, dann übersetzt
Beispiel: “Hello world” → “Hallo Welt”
Warum sind Transformer so revolutionär?
Vorher (alte Methoden):
- Computer lasen Texte Wort für Wort von links nach rechts
- Langsam und vergaßen oft den Anfang des Textes
- Wie jemand, der nur ein Wort nach dem anderen lesen kann
Transformer:
- Sehen alle Wörter gleichzeitig
- Verstehen Zusammenhänge über weite Strecken
- Viel schneller, weil parallel verarbeitet wird
- Wie jemand, der den ganzen Text auf einmal erfasst
Top 10 Post-Transformer
Was kommt als Nächstes? Die KI-Forschung entwickelt sich schnell weiter. Hier sind einige neue Ansätze, die möglicherweise die Zukunft prägen, aber noch nicht weit verbreitet sind:
Übersicht
| Rang | Modelltyp | Was ist anders? | Besonderheit | Transformer-basiert | Beispiele/Status |
|---|---|---|---|---|---|
| 1 | State Space Models (SSM) | Sequenzmodell ohne klassische Attention; lineare Skalierbarkeit O(n) statt O(n²) | 5× schnellere Inferenz, Verarbeitung von Millionen-Token-Sequenzen | ❌ Nein | Mamba, Mamba-2, Jamba (AI21), IBM Bamba |
| 2 | Neural Memory Architectures | Dynamische Speicher-Module mit Kurz- und Langzeitgedächtnis, lernen zur Testzeit | Skalierung auf 2M+ Token, “Needle-in-Haystack” Aufgaben, überraschungsbasiertes Lernen | ⚠️ Hybrid | Google Titans, Sakana NAMMs |
| 3 | Self-Adaptive Models | Dynamische Gewichtsanpassung zur Laufzeit ohne Retraining | Singular Value Fine-tuning (SVF), Spezialisierung durch “Expert”-Vektoren | ✅ Ja | Sakana Transformer², SVF |
| 4 | Mixture-of-Experts (MoE) | Viele Teilmodelle (“Experten”), nur wenige aktiv pro Input | Riesige Skalierbarkeit bei geringeren Kosten pro Anfrage | ✅ Ja (meist) | GPT-4, Gemini Ultra, MoE-Mamba |
| 5 | Continuous Computation Models | Zeitdynamik auf Neuron-Ebene, interne “Denkschritte” unabhängig von Input | Biologisch inspiriert, sequentielle Verarbeitung wie im Gehirn | ❌ Nein | Sakana CTM, Temporale Netzwerke |
| 6 | Test-Time Compute Models | Zusätzliche Rechenzeit während Inferenz für bessere Ergebnisse | “Denken” länger über schwierige Probleme, Chain-of-Thought zur Laufzeit | ✅ Ja | OpenAI o1, o3 |
| 7 | Multimodale Modelle | Text, Bild, Audio, Video in einheitlicher Architektur verarbeitet | Kombinierte Verständnis & Generierung über Datentypen hinweg | ✅ Ja | GPT-4o, Gemini Pro, Claude 3 |
| 8 | Retrieval-Augmented Generation | Externe Wissensquellen dynamisch zur Laufzeit einbinden | Zugriff auf aktuelle Informationen, reduziert Halluzinationen | ✅ Ja (meist) | RAG-Systeme, Perplexity |
| 9 | Diffusionsmodelle für Text | Schrittweise Rauschentfernung statt direktes Sampling | Präzise Kontrolle über Stil, Struktur und Textgenerierung | ⚠️ Hybrid | Experimentelle Textgeneratoren Diffusionmodel |
| 10 | Neurosymbolische Ansätze | Kombination neuronaler Netze mit symbolischer KI und Logik | Verbesserte Reasoning-Fähigkeiten und logische Schlussfolgerungen | ⚠️ Hybrid | Forschungsprototypen, Logic-LMs |
Legende:
Transformer-basiert:
- ✅ Ja: Basiert vollständig auf Transformer-Architektur
- ❌ Nein: Komplett neue Architektur ohne Transformer-Komponenten
- ⚠️ Hybrid: Kombiniert Transformer mit anderen Ansätzen
Entwicklungsstatus:
- Produktiv: Bereits in kommerziellen Produkten verfügbar
- Experimentell: Funktionsfähige Prototypen, noch nicht produktionsreif
- Forschung: Frühe Forschungsphase, Konzeptnachweis
Trends für 2025:
- Memory-Revolution: Architekturen mit neuralen Gedächtnis-Modulen
- SSM-Adoption: Lineare Skalierung wird Standard für lange Sequenzen
- Runtime-Adaptation: Modelle passen sich dynamisch ohne Retraining an
- Hybrid-Ansätze: Kombination verschiedener Architekturen für optimale Leistung
Warum ist das wichtig? Diese neuen Ansätze könnten in Zukunft die Transformer-Dominanz herausfordern, besonders wenn es um Effizienz und Geschwindigkeit geht.
Abgrenzung zu verwandten Dokumenten
| Dokument | Frage |
|---|---|
| Tokenizing & Chunking | Wie wird Text für Modelle in verarbeitbare Einheiten zerlegt? |
| Embeddings | Wie wird Bedeutung als Vektor darstellbar gemacht? |
| Fine-Tuning | Wann reicht die Grundarchitektur nicht mehr und Anpassung per Training wird relevant? |
Version: 1.0
Stand: November 2025
Kurs: Generative KI. Verstehen. Anwenden. Gestalten.